Show that the circuits in Figures 15.1 and 15.2 differentiate, integrate, sum, and difference.
I’ll take as given that op amps with negative feedback keep their two input terminals at the same voltage. I also assume ideal op-amps that draw no current from their inputs. All the proofs follow from Kirchhoff’s current law (aka conservation of charge). I write to refer to the resistor in the feedback path. All schematics are from Wikimedia Commons.
For the integrator, current through the resistor must equal current through the capacitor.

For the differentiator, current through the capacitor must equal current through the resistor.

For the summing amplifier, the sum of the currents through the input resistors must equal the current through the feedback resistor.

For the difference amplifier, neither input terminal is grounded, so we can’t assume they’re at zero volts. Call their voltage . I’ll also assume both resistors and in the above schematic are the same, which I’ll call . Applying Kirchhoff’s current law to the non-inverting input,
Then looking at the inverting input,
Design a non-inverting op-amp amplifier. Why are they used less commonly than inverting ones?

Connect the signal you want to amplify to the non-inverting input. Then create a voltage divider, connected to ground on one end, the inverting input in the middle, and the output on the other end. I’ll call the resistor connected to ground , and the feedback resistor as before.
A potential downside is that the gain must be at least unity. Additionally the nodes aren’t tied to ground, so if the op-amp has imperfect common-mode rejection we’ll see it in the output. A potential upside is that the input impedance is very high. And, of course, the output isn’t inverted.
Design a transimpedance (voltage out proportional to current in) and a transconductance (current out proportional to voltage in) op-amp circuit.

For a transimpedance amplifier, replace the input resistor in an inverting amplifier with a wire. Then the current flowing through the feedback resistor is equal to the current at the input. So , and .
For a transconductance amplifier, replace the feedback resistor with a wire. Then the current out is . If you want a non-inverting transconductance amplifier, connect the input straight to the non-inverting terminal and connect the inverting terminal to ground via a resistor . Then .
Derive equation (15.16).
The currents flowing through , , and must be equal. Call this current (I’ll take left to right to be positive for all currents). Because of the negative feedback, the inverting input of the op-amp is a virtual ground. Recall that , so . Thus we can express three ways:
I’m using to denote the voltage at the junction between and . Differentiating the first two lines yields
Thus
As such we can write the current through the capacitor as
This can still be equated
So all that remains is to solve for .
This differs in sign from (15.16) because the book makes the positive current direction right to left.
If an op-amp with a gain–bandwidth product of 10 MHz and an open-loop DC gain of 100 dB is configured as an inverting amplifier, plot the magnitude and phase of the gain as a function of frequency as is varied.
A lock-in has an oscillator frequency of 100 kHz, a bandpass filter Q of 50 (re- member that the Q or quality factor is the ratio of the center frequency to the width between the frequencies at which the power is reduced by a factor of 2), an input detector that has a flat response up to 1 MHz, and an output filter time constant of 1 s. For simplicity, assume that both filters are flat in their passbands and have sharp cutoffs. Estimate the amount of noise reduction at each stage for a signal corrupted by additive uncorrelated white noise.
For an order 4 maximal LFSR work out the bit sequence.
Table (13.1) indicates that a maximal LFSR of order 4 is . The bit sequence has to repeat in a cycle of length . The bits are 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0.
If an LFSR has a chip rate of 1GHz, how long must it be for the time between repeats to be the age of the universe?
The age of the universe is 13.7 billion years, which is about seconds.
Assuming a flat noise power spectrum, what is the coding gain if the entire sequence is used to send one bit?
I think the coding gain works out like the SNR I derive in the next problem… but could be wrong.
What is the SNR due to quantization noise in an 8-bit A/D? 16-bit? How much must the former be averaged to match the latter?
This depends on the characteristics of the signal. Assuming that it uses the full range of the A/D converter (but no more), and over time is equally likely to be any voltage in that range, then the SNR in decibels is
where is the number of bits used.
So we have
But where does this come from? Recall that the definition of the SNR is the ratio of the power in the signal to the power in the noise. Let’s say we have an analog signal within the range . Let its time-averaged distribution be . Then the power in the signal is
Let’s assume that the signal is equally likely to take on any value in its range, so . This is completely true of triangle waves and sawtooth waves, relatively true for sin waves, but not true at all for square waves. So this approximation may or may not be very accurate. Then its power is
When the signal is quantized, each measurement is replaced with a quantized version. The most significant bit tells us which half of the signal range we’re in. In this case that means whether we’re in the range [-A, 0] or [0, A]. Note that each interval is long. The next bit tells us which half of that half we’re in. Each interval is long. So finally the least significant bit will tell us which half of a half etc. we’re in, and each interval will be long (or equivalently ), where is the number of bits.
The uncertainty we have about the original value is thus plus or minus half the least significant bit. So the quantization error will be in the range . Since we’re assuming our signal is equally likely to take any value, the quantization error is equally likely to fall anywhere in this range. Thus the power in the quantization noise is
Putting it together,
The message 00 10 01 11 00 (, ) was received from a noisy channel. If it was sent by the convolutional encoder in Figure 15.20, what data were transmitted?
This problem is harder than the others.
My code for all sections of this problem is here. All the sampling and gradient descent is done in C++ using Eigen for vector and matrix operations. I use Python and matplotlib to generate the plots.
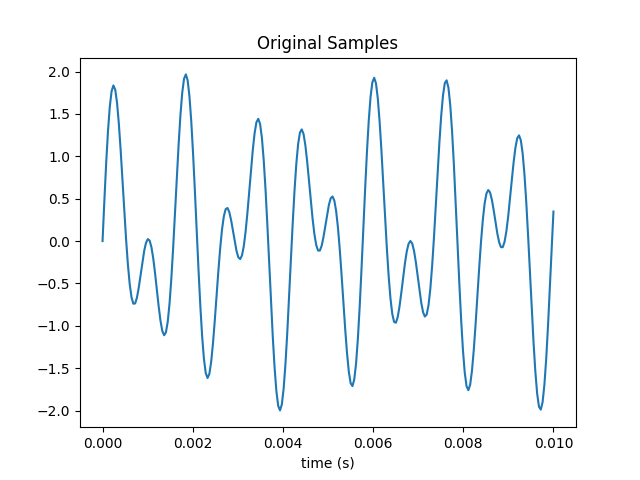
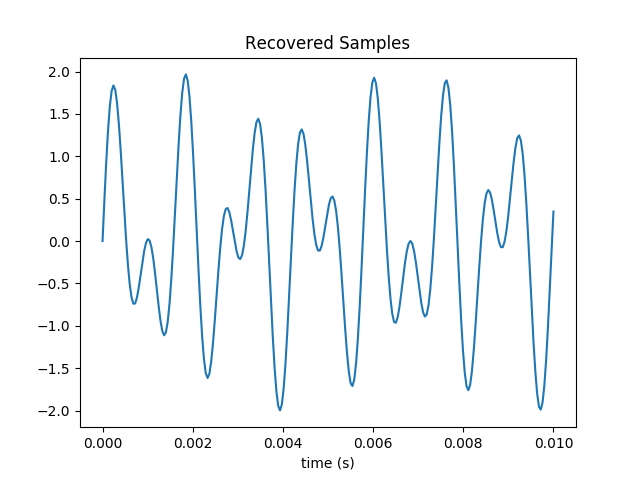
Generate and plot a periodically sampled time series {} of N points for the sum of two sine waves at 697 and 1209 Hz, which is the DTMF tone for the number 1 key.
Here’s a plot of 250 samples taken over one tenth of a second.
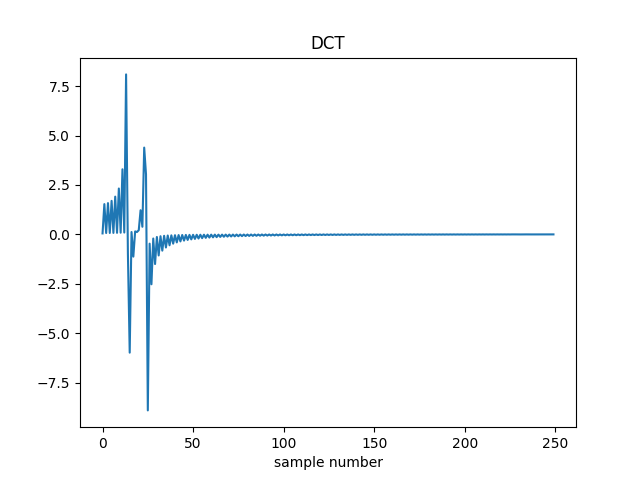
Calculate and plot the Discrete Cosine Transform (DCT) coefficients {} for these data, defined by their multiplication by the matrix , where
Plot the inverse transform of the {} by multiplying them by the inverse of the DCT matrix (which is equal to its transpose) and verify that it matches the time series.
The original samples are recovered.
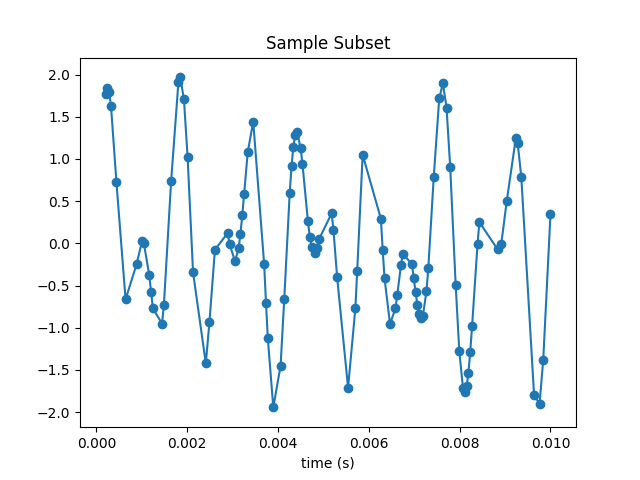
Randomly sample and plot a subset of M points {} of the {}; you’ll later investigate the dependence on the sample size.
Here I’ve selected 100 samples from the original 250. The plot is recognizable but very distorted.
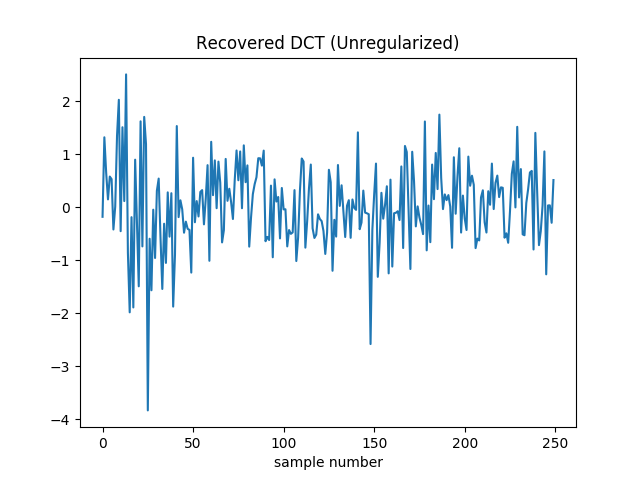
Starting with a random guess for the DCT coefficients {}, use gradient descent to minimize the error at the sample points
and plot the resulting estimated coefficients.
Gradient descent very quickly drives the loss function to zero. However it’s not reconstructing the true DCT coefficients.
To make sure I don’t have a bug in my code, I plotted the samples we get by performing the inverse DCT on the estimated coefficients.
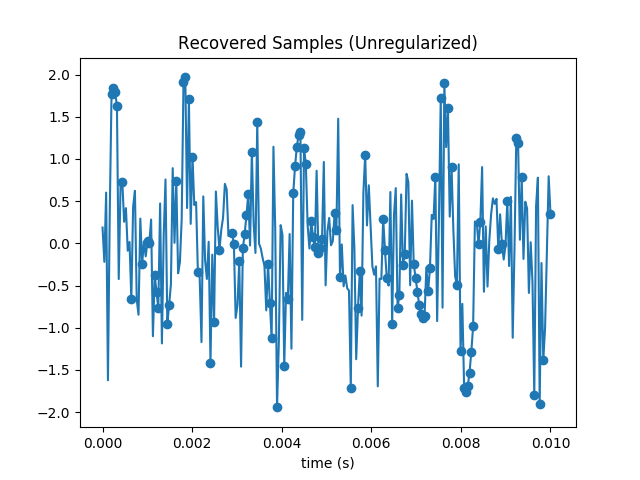
Sure enough all samples in the subset are matched exactly. But the others are way off the mark. We’ve added a lot of high frequency content, and are obviously overfitting.
The preceding minimization is under-constrained; it becomes well-posed if a norm of the DCT coefficients is minimized subject to a constraint of agreeing with the sampled points. One of the simplest (but not best [Gershenfeld, 1999]) ways to do this is by adding a penalty term to the minimization. Repeat the gradient descent minimization using the L2 norm:
and plot the resulting estimated coefficients.
With L2 regularization, we remove some of the high frequency content. This makes the real peaks a little more prominent.
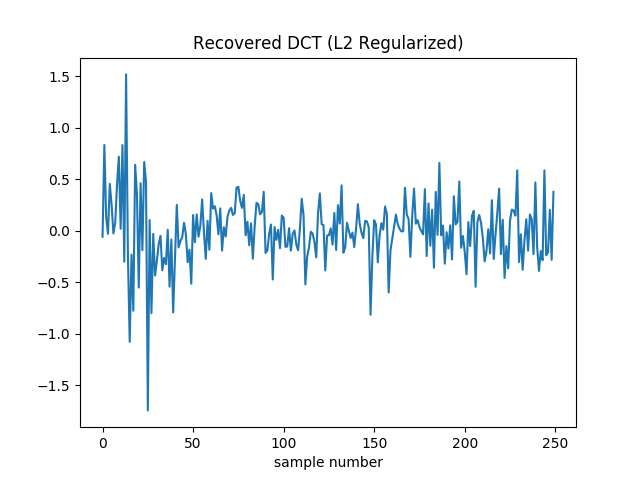
However it comes at a cost: gradient descent no longer drive the loss to zero. As such the loss itself isn’t a good termination condition. In its place I terminate when the squared norm of the gradient is less than . The final loss for the coefficients in the plot above is around 50.
You can easily see that the loss is nonzero from the reconstructed samples.
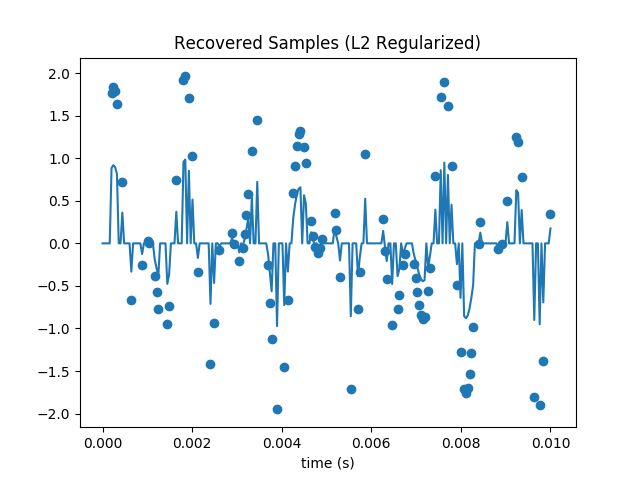
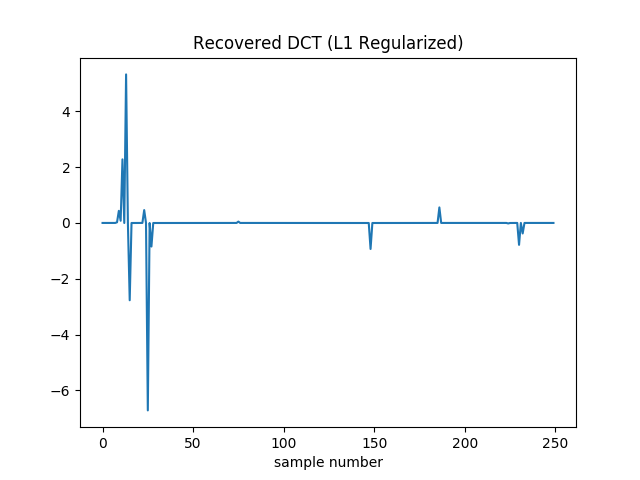
Repeat the gradient descent minimization using the L1 norm:
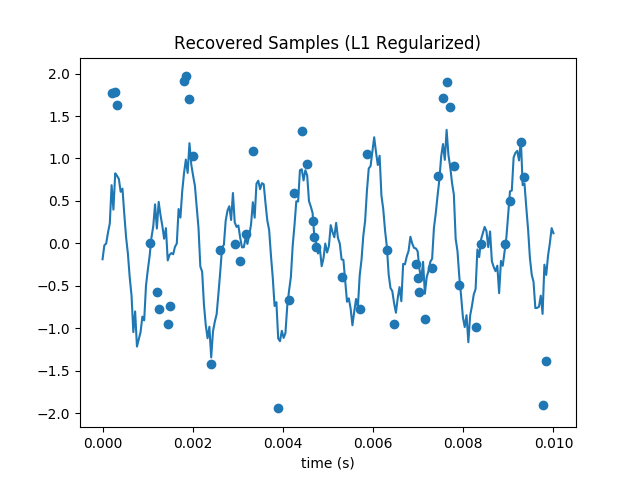
Plot the resulting estimated coefficients, compare to the L2 norm estimate, and compare the dependence of the results on M to the Nyquist sampling limit of twice the highest frequency.
With L1 regularization the DCT coefficients are recovered pretty well. There is no added high frequency noise.
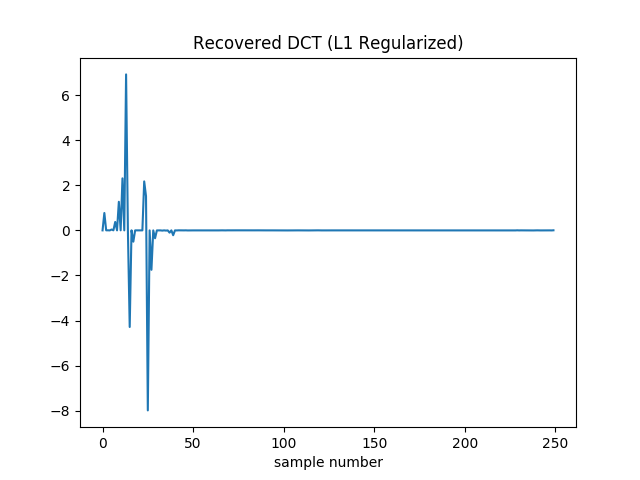
It still can’t drive the loss to zero. Additionally it’s hard to drive the squared norm of the gradient to zero, since the gradient of the absolute values shows up as 1 or -1. (Though to help prevent oscillation I actually drop this contribution if the absolute value of the coefficient in question is less than .) So here I terminate when the relative change in the loss falls below . I also decay the learning rate during optimization. It starts at 0.1 and is multiplied by 0.99 every 64 iterations.
The final loss is around 40, so better than we found with L2 regularization. However it did take longer to converge: this version stopped after 21,060 iterations, as opposed to 44 (for L2) or 42 (for unregularized). If I stop it after 50 samples it’s a bit worse than the L2 version (loss of 55 instead of 50). It’s not until roughly 2500 iterations that it’s unequivocally pulled ahead. I played with learning rates and decay schedules a bit, but there might be more room for improvement.
The recovered samples are also much more visually recognizable. The amplitude of our waveform seems overall a bit diminished, but unlike our previous attempts it looks similar to the original.
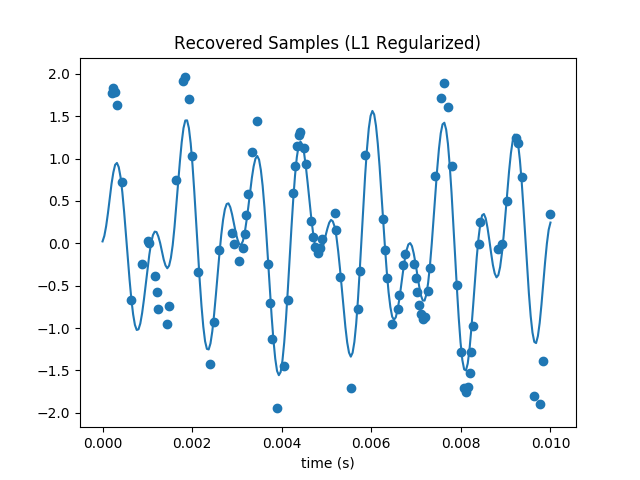
This technique can recover the signal substantially below the Nyquist limit. The highest frequency signal is 1209 Hz, so with traditional techniques we’d have to sample at 2418 Hz or faster to avoid artifacts. Since I’m only plotting over one hundreth of a second, I thus need at least 242 samples. So my original 250 is (not coicidentally) near here. But even with a subset of only 50 samples, the L1 regularized gradient descent does an admirable job at recovering the DCT coefficients and samples: