This is how you initially download a repo (short for repository). In our case the urls look like
https://gitlab.cba.mit.edu/classes/863.19/[YOUR SECTION]/[PROJECT WITHIN SECTION]
So if you're in the architecture section, you would run
git clone https://gitlab.cba.mit.edu/classes/863.19/Architecture/archsite.git
You can find this url on the top-right of the GitLab project, by clicking the "clone" button.
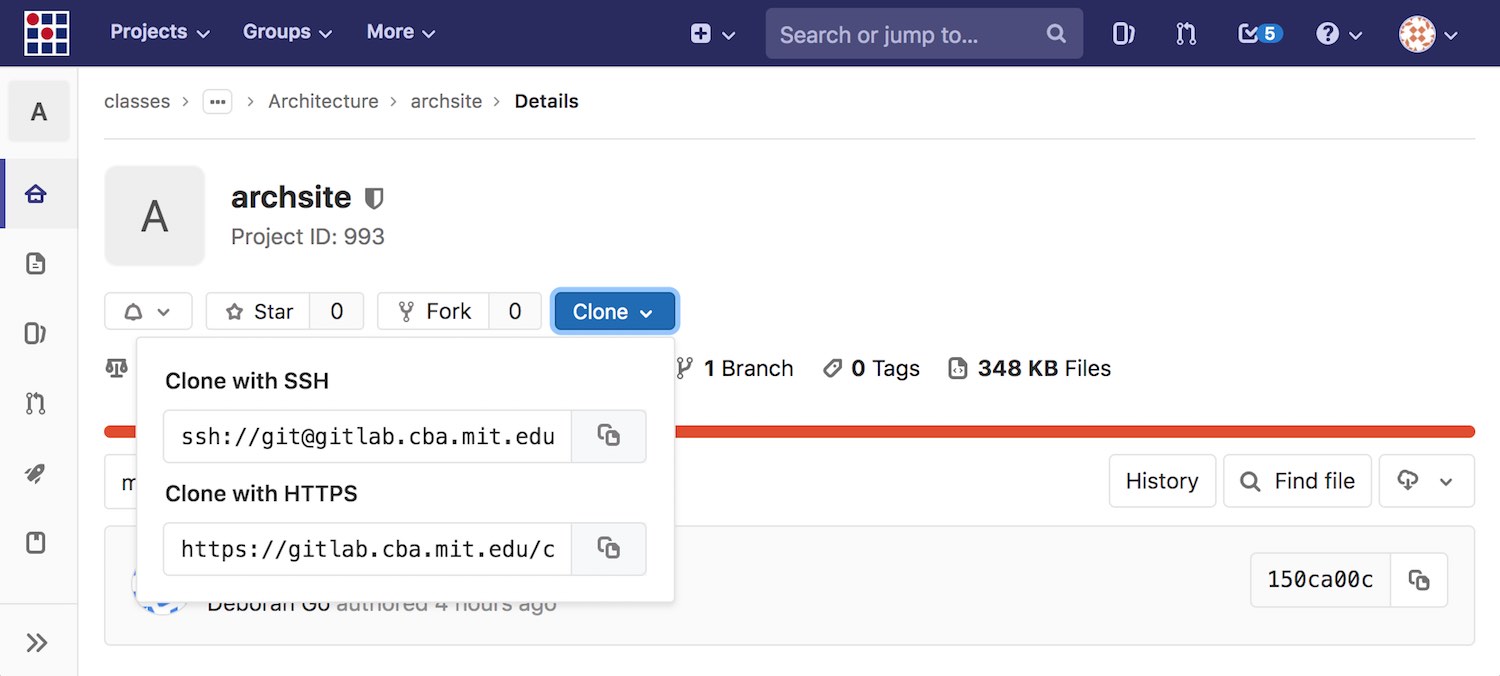
Only use the SSH version if you've set up an SSH key on your computer and GitLab. (This means you won't have to type in your username and password, but requires a little bit of setup.) If you're just getting started go ahead and use HTTPS. After cloning, you'll have the repo locally on your computer.
When you create a file, you have to tell git to track it and care about it, otherwise it won't version it. And when you modify a file, you have to tell git when you want it to record the changes. "git add" is used for both of these. So if you make (or modify) a file called index.html, you would run
git add index.html
You can also use * in a filename as a wildcard, for instance, git add * will add all files in your directory, git *.html will add all html files in your directory.
Note that git add by itself doesn't make a commit; for that you need to run, well, git commit. It works this way so that you can add (a.k.a. stage) multiple files and then make one commit that contains the changes to all of them.
A commit versions your files LOCALLY, meaning when you commit your changes, it creates a snapshot that you can revert to at any time. If you've used git add to stage some changes, you just need to run
git commit
This will open up a text editor so that you can type a commit message (you can choose which one it uses like this). Usually it's faster to use
git commit -m"Your commit message here"
which just includes the commit message in the command itself.
The commit message should describe what you changed. All the commit messages are visible on gitlab (and from git — try running git log) and can help you navigate to old versions in case you need to go backward for some reason.
If you want to commit all the files you've changed without having to add them first, you can run
git commit -am"Your commit message here"
If you're going to use this command, you should get in the habit of checking which files are modified by running
git status
and
git diff
Otherwise you'll end up committing things you didn't intend to sooner or later.
This brings all new changes on the gitlab server into your working directory. Think of it as git clone, but only for new changes. In some cases, the pull will conflict with local changes — this should be rare in this class as long as you push after you commit. If it happens, merge the differences of the files that say there's a conflict, test that everything works properly, and then commit the changes.
Remember how commits create snapshots local to your computer? "git push" sends all those snapshots to the server, and makes them "live." Until you do this, nothing you do will be on the server. You can think of git push as "git upload," if you'd like. You probably want to run "git push" right after you run git commit, to keep the central GitLab repo and your local copy in sync. (This doesn't apply if you're fancy and use your own development branches.)