This week was the group project. I was in the CBA Machine Group.
Simulating the algorithm 🔗
After the meeting where we proposed the algorithm, I wanted to try to communicate my concern about the bias in the algorithm (I thought it was fine that the algorithm was biased, and kind of funny. but wanted more folks to be aware of it.) It’s easier to do with a simulation: just run through 100000 fake decisions. So I jotted down an initial implementation of the algorithm in numpy.
Biased method 🔗
Even if the coin was totally fair, we suspected the algorithm was fundamentally biased: things lower in the list get a different number of coin flips than those at the top. But this can be hard to reason about and explain, so it’s easier to just run a simulation.
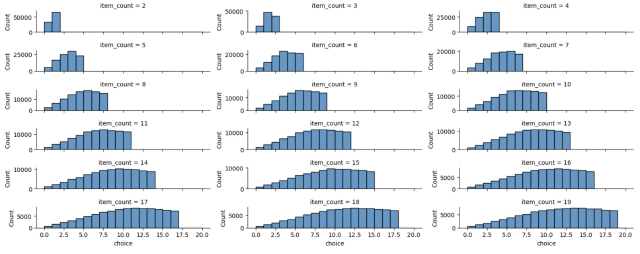
Here, we make 100,000 decisions with our biased algorithm, in cases where the number of decisions ranges from 2 to 20. We plot the histogram of how many of those decisions picked the choice at index i.
If this was not biased by the decision index, it would be uniform. These are clearly not uniform!
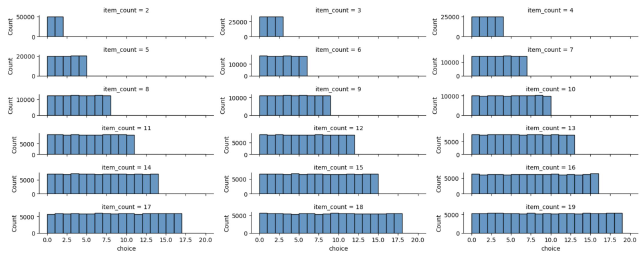
We also tested an alternate algorithm and showed that it was not biased. In this algorithm, we flip the coin $ceil(log_2(n))$ times, and convert the result into a value between 0 and $2^{ceil(log2(n))}$. If the result is within the choices, we choose that one. If it’s not, we reflip $ceil(log_2(n))$ times.
Quantifying very slow decisions 🔗
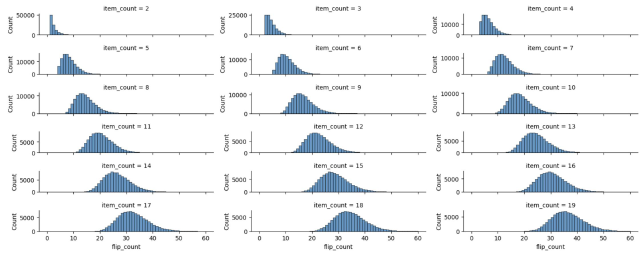
There’s another concern with both algorithms: if you are exceedingly unlucky, you could end up flipping coins for a long time. We set an upperbound so the machine can give up on making a decision if it’s flipped for MAX_COIN_FLIPS times.
Software group 🔗
Michelle was running software, and I was on the software team. She asked if I could implement the algorithm part of the code. I made a decision service.
Implementing the decisions 🔗
Ideally we’d be able to switch between the two algorithms. For this reason, the order of operations is made to work with both.
start iterating:
- Check if we were told to strike through 0 or more items. This will be empty the first iteration. (since the more-fair algorithm strikes 0 or multiple items per coin flip.)
- Check if a decision has been made. If so, break.
- Finally flip a coin, process the result (deciding what will be striked through or if a decision was made), and go through the loop again.
Decision Making Service 🔗
The decision making service was written to be a central control. It initalizes the cameras and machine, and makes calls to the electrical engineering code and the computer vision code to execute the pieces needed for the algorithm. It also acts as a server that the UX can call, to either start a new game or to take a peek at what step the algorithm is at.
Configurations 🔗
We have a configuration file to adjust exact values, such as how many units are needed to reach the x and y coordinates of the first item of the list. This made it trivial to fix it when the machine was striking lines slightly too high, or in the wrong direction.
There are also command line configurations to choose which external services to rely on: camera or the machine. This made it possible to run the service without any physical pieces, with just the camera, with just the machine, or both. (these are required to be specified after an embarassing case of using the mock CV results and being confused why the CV algorithm was acting funny.)
Barebones UX 🔗
I put together a really basic HTML that called the service in the right way.
python decision_maker_service.py --mock-machine --mock-cv
(you can switch the mock to use for any or both of the machines.)
That way the UX team (zak and francisco) could iterate on it independentally.
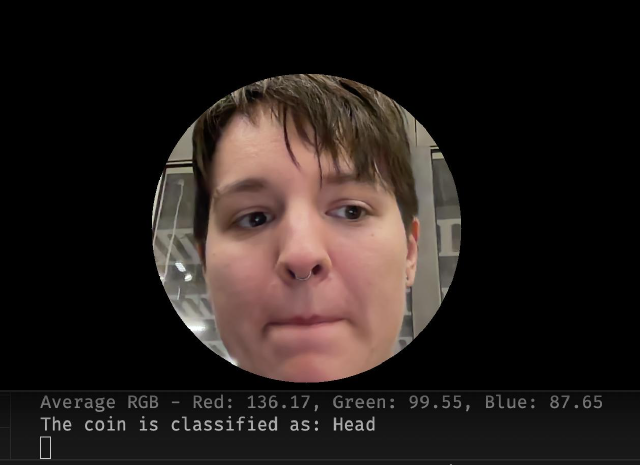
I also integrated Michelle’s camera output, which I’d never done before. It initially classified my face as Head. I used the route of taking a picture and writing it to the response of an endpoint when it’s requested. The page then pings the server to take a snapshot of the current state of the algorithm and images from the camera.
Group leading 🔗
After recitation the week before, I was assigned to lead the group, so I activated my staff engineering skills.
I’d only ever built software projects. With those, I usually have an intuition of how to split up the project. But here, I did not. So I nominated Jonny to help figure out how to split up the project.
I like processes that give everyone a chance to give a say, even if they can’t make a specific meeting. So early on, I would do “write in this doc for X days, we’ll talk through it at a meeting at Y”. Ideally, if someone has strong feelings they can get them articulated before the meeting. (One thing I have leftover from working at a transatlantic company is being very anti-in-person-meeting, since you usually only got one hour slot every few weeks to actually sync across the entire team. In this case, I think we actually did make decisions after a 2 hour meeting… And a lot of the work was done by us hanging out in the shop for hours.)
I had started with notifications going out on the email list, since I knew everyone was on there. And the brainstorming in a Google Doc. When the work actually began, it was more useful to have a stream-of-conscious place, so we told everyone to get on Discord, and updated the Google Doc to be a “messy whiteboard in the lab space” that folks could use as needed.
(I decided with a short timespan, to just enact ways that have worked for me in the past instead of deciding everything. I think in larger projects, it works out to start with a “for this process, we’re going to do it this way”, and then you refine the process as a group through retrospectives.)
So now that everyone had their suggestions written… we needed to make a decision. Here I was not very good. (I realize, I’m used to getting the product decided by the product team, we negotiate a bit, but at least we have an idea to start with, and some authority choosing something.) We talked through a few ideas, went back to the drawing board a few times, and by the end of the meeting, we fell onto the new idea of a decision-making machine that gained a lot of support.
At the Wednesday decision making meeting, we finalized those decisions: there was a mechanical engineering, electrical engineering, and software engineering group (with UX rolled in). There was also a website and video group. At that meeting, we chose points-of-contacts. This works differently in different teams, but I find that giving an individual a stake in a segment of the project helps a lot: they can decide how to break up work in this section, how to get cross-team problems solved, etc. (In my experience in the industry, this was nice too, because it would train people up to lead entire projects. It’s also really nice for me as a staff engineer, cuz I my workload eases and sometimes I can move back into areas that I am also useful.)