Work out the first three cumulants , , and .
Let be any random variable. The cumulants of are defined as the coefficients in the following power series (in ) for the logarithm of the characteristic function. Note that doesn’t appear in the series, since it’s integrated out by the expected value.
So by exponentiating each side, then expanding into a series,
This looks pretty messy, but there’s only so many places terms with low powers of can come from. To help with this, let’s expand the outer sum of the left hand side.
Ok, so both sides clearly start with 1. That checks out. Then to get a single power of , on the left it has to be the first term of the first series (, ), and on the right it has to be the first term ().
So the first cumulant is , the expected value of .
To get , on the left we can use , or , . On the right it has to be .
This is the variance of .
For , there are three relevant terms from the left hand side: , ; , the product of and (this happens two ways so we pick up a factor of 2); and , .
which is the third central moment of .
Stopping here is a little misleading, since fourth and higher order cumulants are not equal to the corresponding central moments. So it goes.
Evaluate the first three cumulants for a Gaussian distribution.
Ok, time to integrate. I’ll start with some basic facts and work my way up from there.
First, the Gaussian distribution is normalized.
If you want to verify this yourself, there are a lot of ways to do it.
Next, the mean of a Gaussian distribution with is 0. This follows from finding an explicit antiderivative.
There’s also a shortcut we could have taken here: is an odd function, while is even. So their product is an odd function, and the integral across the whole real line has to be zero. But we’ll use the antiderivative above in other contexts, so I wanted to work it out fully.
Then the fact that the mean of a general Gaussian distribution is follows from a simple change of variables.
Next, we can integrate by parts to show that is . This uses the same antiderivative we found earlier.
So, using a change of variables again,
To compute , we could integrate by parts again (using and ). But instead I’ll just note that is an odd function, so
Thus
We’re finally ready to plug things together.
It turns out all higher order cumulants of the Gaussian distribution are also zero, and it is the only distribution with this property.
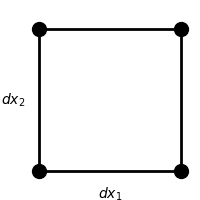
If is a coordinate transformation, what is the area of a differential element after it is mapped into the plane?
The transformation sends a differential element like this
to a parallelogram like this
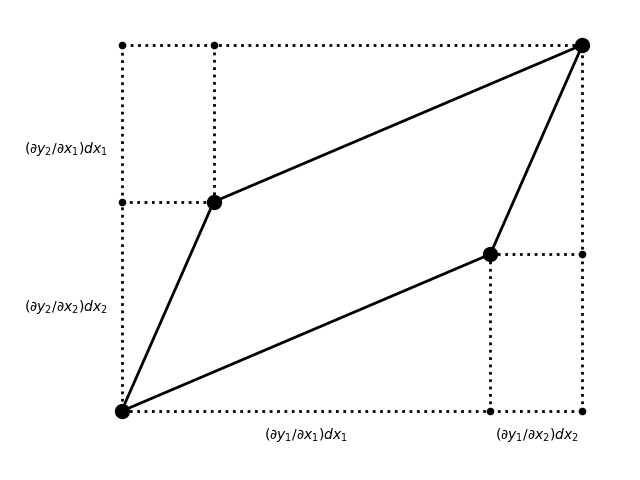
The area of the box containing the parallelogram is
And the area of the triangles and rectangles drawn in dotted lines is
Thus the area of the parallelogram is their difference:
The factor of area change is the absolute value of the determinant of the Jacobian matrix of . (The sign tells us if the handedness of the coordinate system was flipped.)
Let
If is uniform, what is ?
The probability density at a point is
So let’s invert the transform. By squaring and adding both sides, we find that
By dividing the first equation by the second,
So is determined by the radius of the transformed sample, and is determined by its angle. If we sample between 0 and 1, we’ll get radii between 0 and infinity, and if we sample between 0 and , we’ll cover all angles in space. This region of space has area , so the probability density will be uniformly .
So the Jacobian matrix of this (inverse) transformation is
And
Putting the pieces together,
This is the two dimensional normal normal distribution with mean and identity covariance matrix.
Write a uniform random number generator, and transform it by the equations above. Numerically evaluate the first three cumulants of its output.
I implemented a 64 bit xorshift random number generator (code lives here). These generators are mathematically equivalent to LFSRs, but they are more efficient to implement in software. I got the special constants from Numerical Recipes in C, third edition.
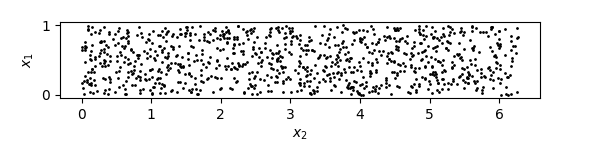
First, let’s make sure it works. Here are 1,000 samples drawn from a uniform distribution on a rectangle of area .
And here are the transformed samples.
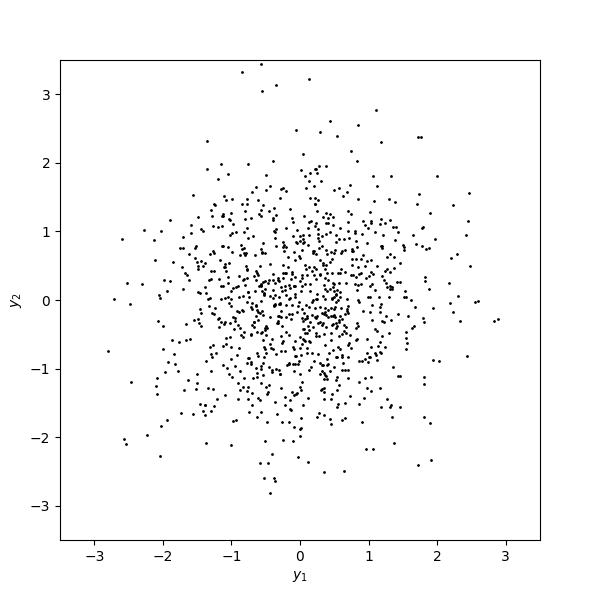
Looks good to me.
Cumulants can be defined for multivariate distributions, but since I already worked out the univariate cases above I’m just going to calculate them for alone. I computed , , and experimentally by taking the average over a large sample of , , and , respectively. Then I just plugged the resulting values into the formulas I found in the previous problem.
With 100,000 samples, I get these values.
With 1,000,000 samples, I get these.
And with one hundred million samples, I get these.
These are consistent with the predicted values.
For an order 4 maximal LFSR write down the bit sequence.
Using taps one and four generates a maximum length bit sequence. I wrote a simple Python program to compute the values for me. The columns are , , , and .
[0 0 0 1]
[1 0 0 0]
[1 1 0 0]
[1 1 1 0]
[1 1 1 1]
[0 1 1 1]
[1 0 1 1]
[0 1 0 1]
[1 0 1 0]
[1 1 0 1]
[0 1 1 0]
[0 0 1 1]
[1 0 0 1]
[0 1 0 0]
[0 0 1 0]
If an LFSR has a clock rate of 1 GHz, how long must the register be for the time between repeats to be the age of the universe (~ years)?
A maximal LFSR of order has a cycle of length . There are seconds in a year.
So you’d need 92 bits to exceed the age of the universe.
I used Wolfram Alpha to compute the logarithm above, but we can also estimate it ourselves. Recall that , so to change from base 10 to base 2 we just need to multiply the exponent by about 3.
This is a little under the real answer since I multiplied the exponent by 3 rather than . But order of magnitude wise it’s completely fine.
Use a Fourier transform to solve the diffusion equation (assume that the initial condition is a normalized delta function at the origin).
For reference, the diffusion equation is
There are two different conventions about where to stick the constants in the definition of the Fourier transform; I will use the one in my handy Fourier transform notes.
Taking the Fourier transform of both sides with respect to , we find
Recall that the Fourier transform of a derivative just picks up a factor of (this is derived in my Fourier transform notes).
Let’s try the ansatz .
So . Now if is a normalized delta function, then is uniformly 1. Thus .
As derived in my Fourier transform notes, this is the transform of a Gaussian with zero mean and variance . Thus
What is the variance as a function of time?
We already demonstrated that is a Gaussian with zero mean and variance . So the variance grows linearly over time.
How is the diffusion coefficient for Brownian motion related to the viscosity of a fluid?
In the chapter we found that
Thus, assuming an isotropic and homogeneous fluid, the variance of the particle’s position in the fluid is also , since will be zero.
To model a particle of the fluid with Brownian motion we’ll need to match variances.
Write a program (including the random number generator) to plot the position as a function of time of a random walker in 1D that at each time step has an equal probability of making a step of . Plot an ensemble of 10 trajectories, each 1000 points long, and overlay error bars of width on the plot.
I used the same random number generator as in the previous problem to draw uniform samples from . The trajectories are simply sums of these random variables.
In the chapter we found that the diffusion constant for Brownian motion is . In this case the expected value of is 1, since all possible values of the random variable squared are one (). Our timestep is also . So . Thus , and .
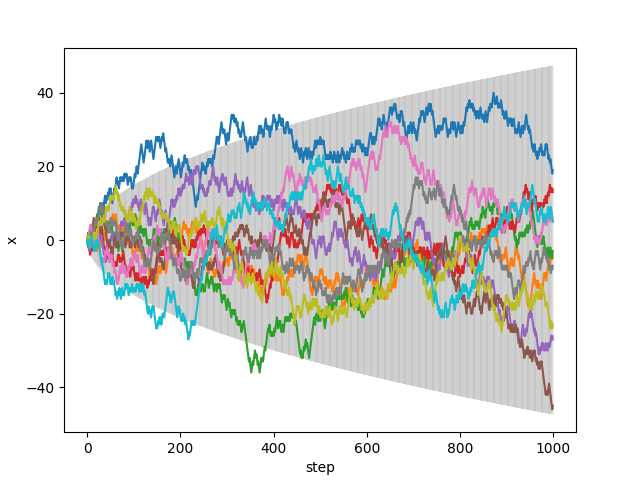
What fraction of the trajectories should be contained in the error bars?
At any given timestep, the positions of the trajectories are normally distributed with variance . So 87% of the trajectories should be within 1.5 standard deviations of the mean. This value can be computed as
Alternatively, you can look it up like I did in a standard normal table.
However there’s another way to interpret this question. Let’s try to find the probability that a trajectory has never left the error bars. More formally, we want to know the probability that we end in state and never left the error bars along the way, for each time step . Let’s call this probability .
To start, though, let’s answer a simpler question: how many different paths reach state at time step ? I’ll call this number . If we go back one step in time, there’s only two states a path could have stepped from to get to : and . So satisfies the recurrence relation
This just describes Pascal’s triangle. Thus the number of paths that reach state at time step is exactly choose .
Note that the total number of paths at time step is . Fundamentally this is true because each path splits in two at each time step, but you can also sanity check it by summing the columns of the triangle above. Given this, the probability of reaching state at time step has to be choose divided by :
This ensures that
for all .
Unfortunately this expression for is hard to compute directly, since both the numerator and denominator quickly become unreasonably large. And there’s no simple cancellation of terms that would let us compute the result without enormous intermediate values.
But the recurrence relation that led us to can easily be modified to describe : just multiply by at each step. This ensures the normalization factor of is taken into account.
Visually, this amounts to filling in this triangle of probabilities from left to right. Each number is simply the sum of the two immediately before it, divided by two. All the columns sum to one.
We can use a similar technique to calculate what we really want: , i.e. the probability of reaching state at time step and never having gone outside the error bars along the way. All we need to do is zero out the probabilities that fall outside our bounds.
The columns no longer sum to one, since not all paths that reach in bounds states never went out of bounds beforehand. For reference, here are the standard deviation bounds relevant for the figure above.
| n | 1.5 * sqrt(n) |
|---|---|
| 1 | 1.5 |
| 2 | 2.1 |
| 3 | 2.6 |
| 4 | 3.0 |
| 5 | 3.4 |
Because nonzero probabilities never occur outside , this technique is surprisingly scalable. For instance, there are only 95 nonzero values in the 1,000th column. (Contrast this with , for which there would be 2001 nonzero values, many of which are astronomically large.)
This makes it easy to compute the values for all up to 1,000.
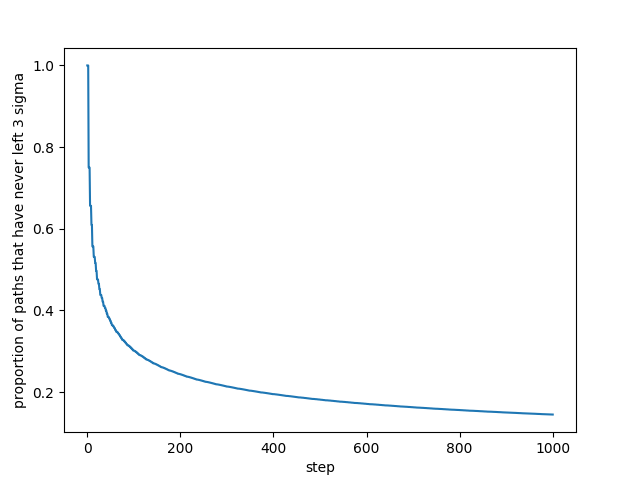
And to answer the specific question we started with, 14.5% of all possible trajectories have never left at step 1000.