Rebecca Kleinberger MAS862.13 Project
Questions
a. What is the goal?
Showing the interest of considering the physical and biological aspects of vocal production when digitally transmitting vocal information
b. To accomplish this, what question will you answer?
Anatomy and mechanisms involved in voice production?
What are the difficulties in studying articulators that can not be accessed or measured easily?
How can they be modeled and what are their (slowly varying) parameters?
What is theorically the computational cost saving for lossless reconstruciton of a voice signal with using a biomechanically informed codec?
c. What technique(s) will you use to answer them?
Matlab coding
- signal processing
- physical modeling
- entropy computation
d. What is the prior art?
literature review
e. How will you evaluate the results?
Organisation
I - Intro: The physics of vocal production
1) Anatomy
2) Mechanisms
3) Filter-Source model
II - From signal to physics
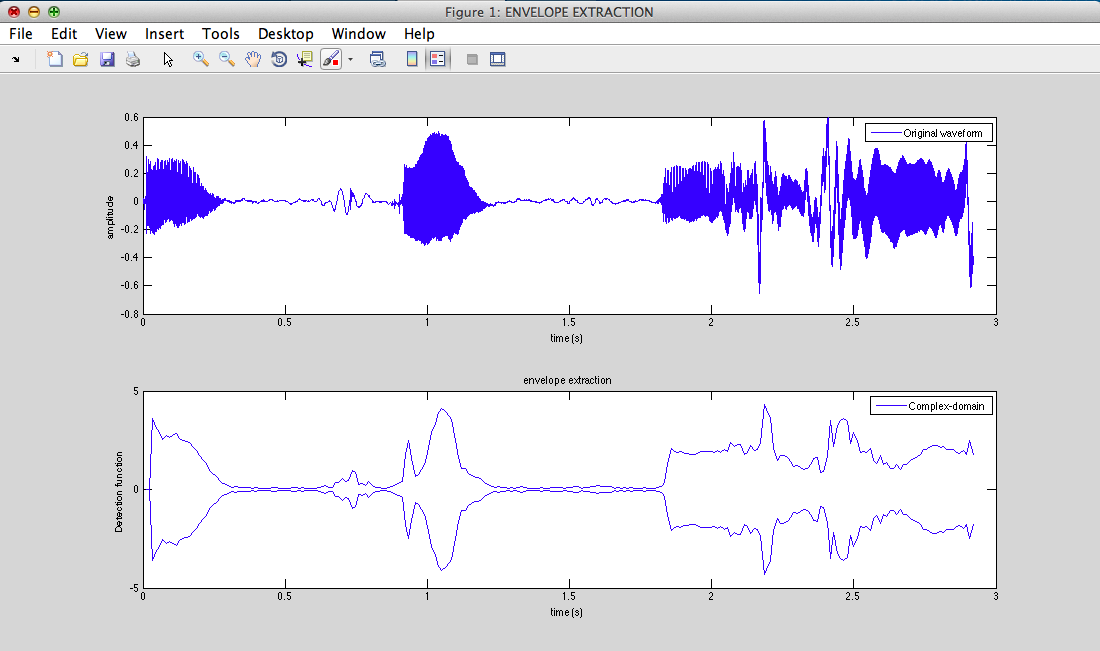
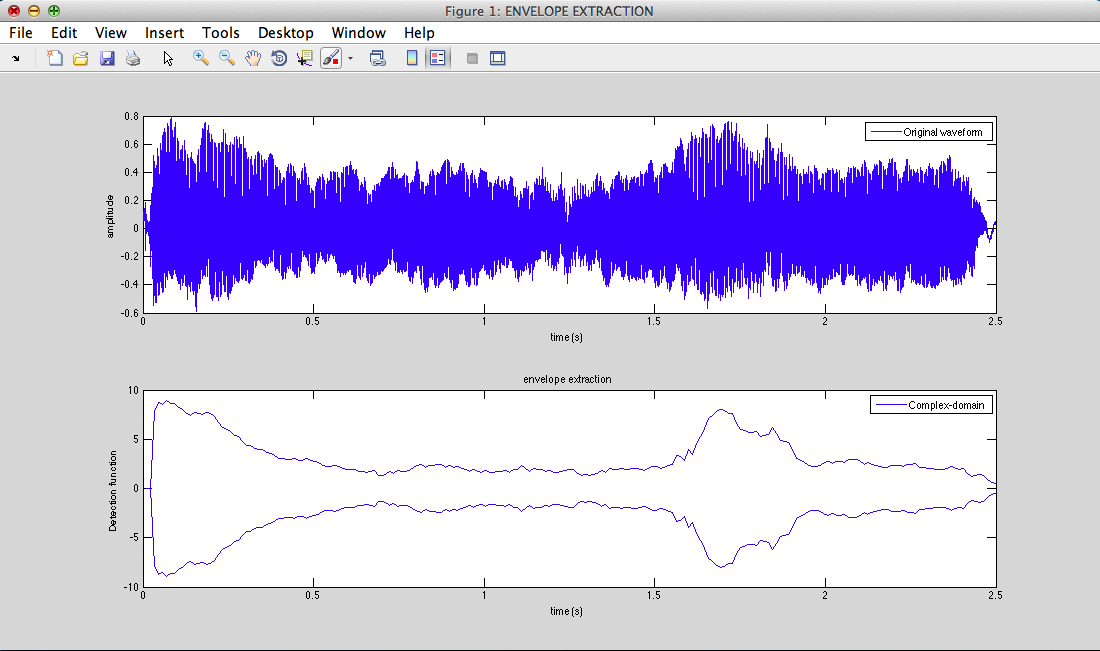
1) Air flow : envelope extraction
2) Glottal signal : estimation of F0
3) Filtration by the cavities
4) Exemples
III - From physics to signal
1) Vocal tract shape
2) Scattering equation
3) Glottal signal model
4) Results
IV - Information theory point of view
1) Entropy in speech in the audio signal paradygm
2) State of the art of low rate of low bit rate coding
3) Encoding of the physical model
I - Introduction: The physics of vocal production
I-1) Anatomy
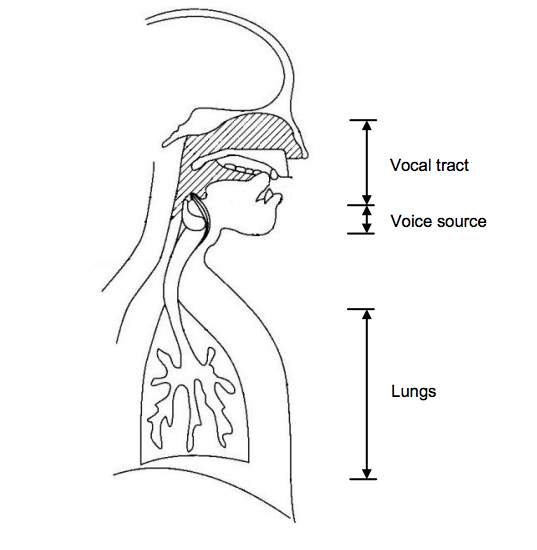
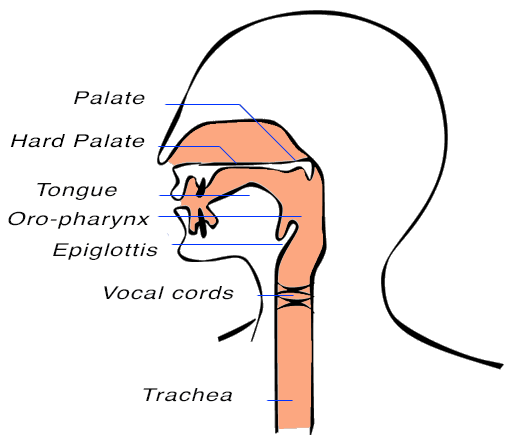
from (1) and
(2)
from (1) and (2)
- Loudness in the range of 55 to 80 dB
- Fundamental frequency from 85 to 180 Hz for an adult male and from 165 to 300Hz for an adult female
- The frequency decomposition is dependent of the vocal tract contraction and thus limited by his shape
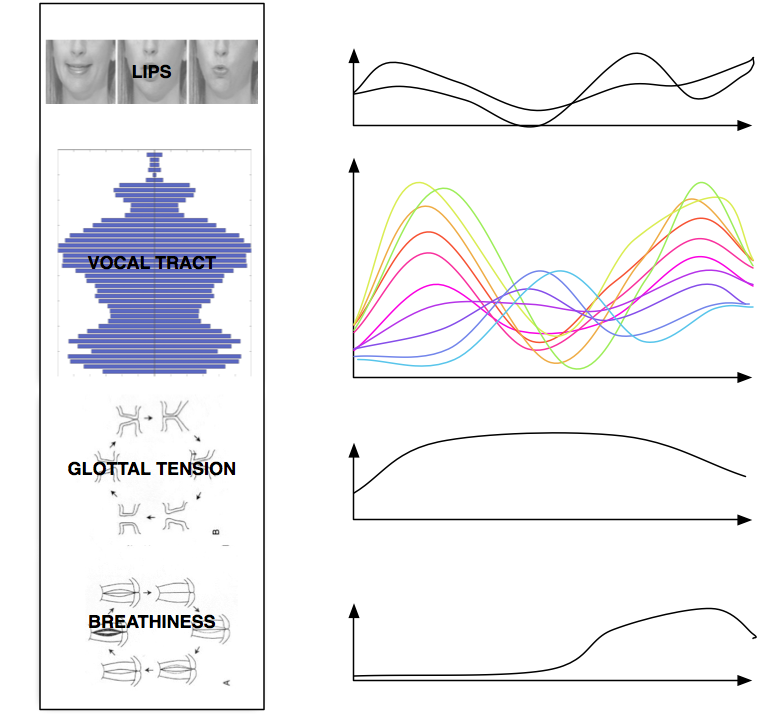
I-2) Mechanisms
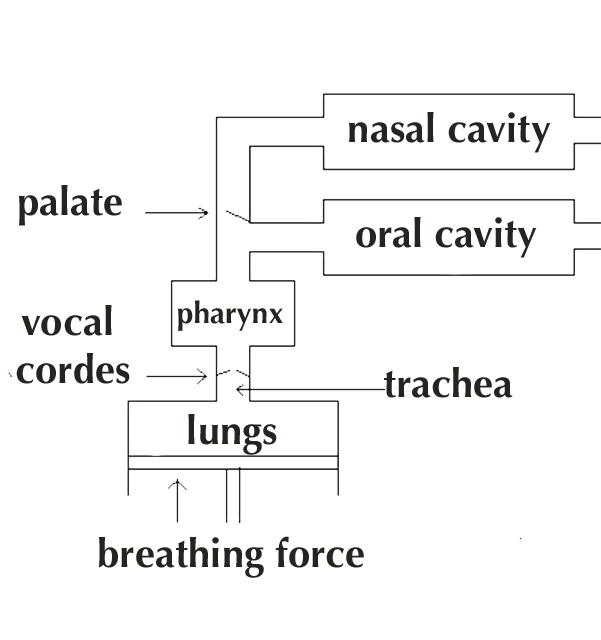
from (4)
We can consider that the voice production results from three phenomena
from (4)
- comes from the diaphragm contraction
- the energy that enables self sustained vibration of the vocal cords
- envelope of the sound signal
- self sustained by air flow
- pitch F0
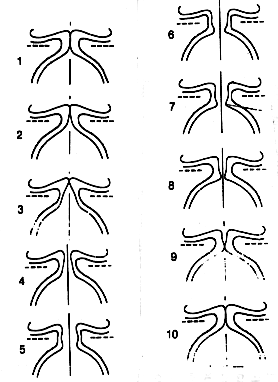
from (5)
- filters the glottal signal by damping or increasing certain frequencies
vowels A and E
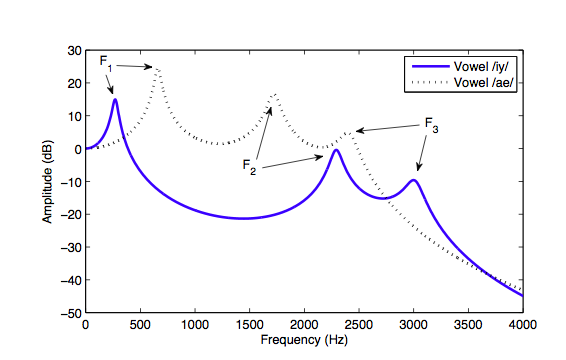
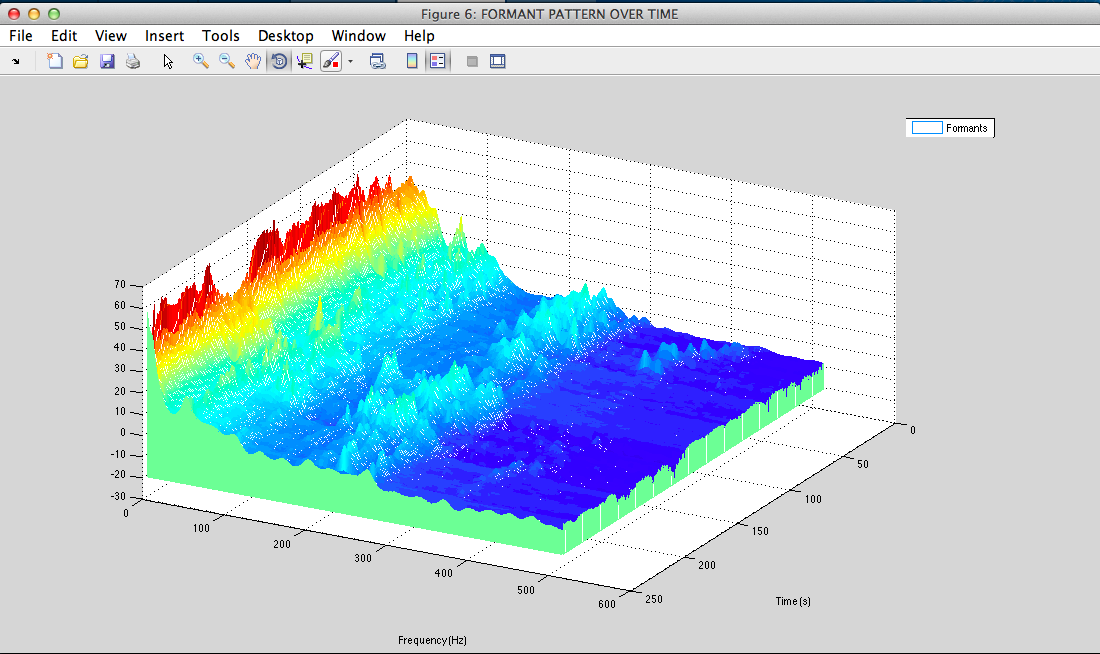
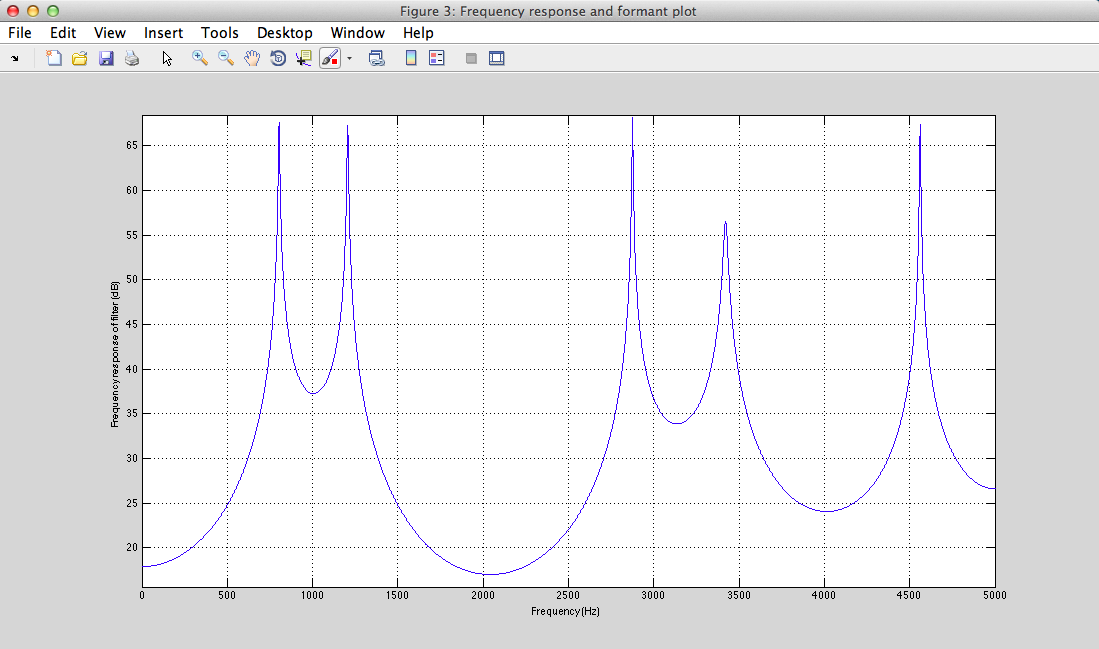
formant patern
I-3) Filter-Source model
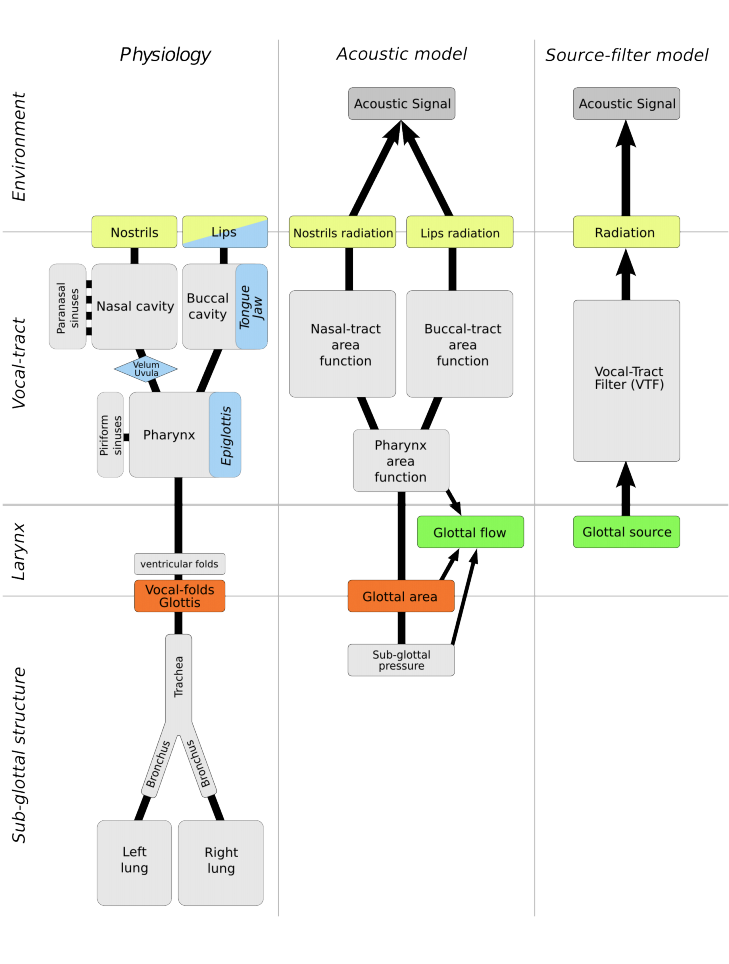
models from (6)
models from (6)
II - From signal to physics :
II - 1) Air flow : envelope extraction
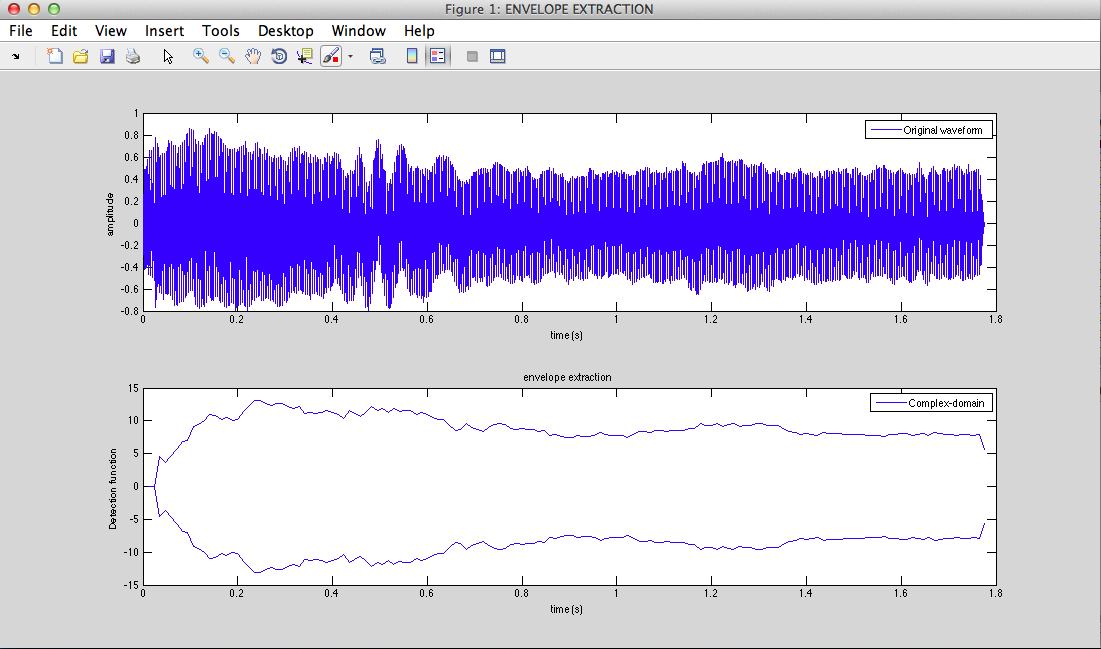
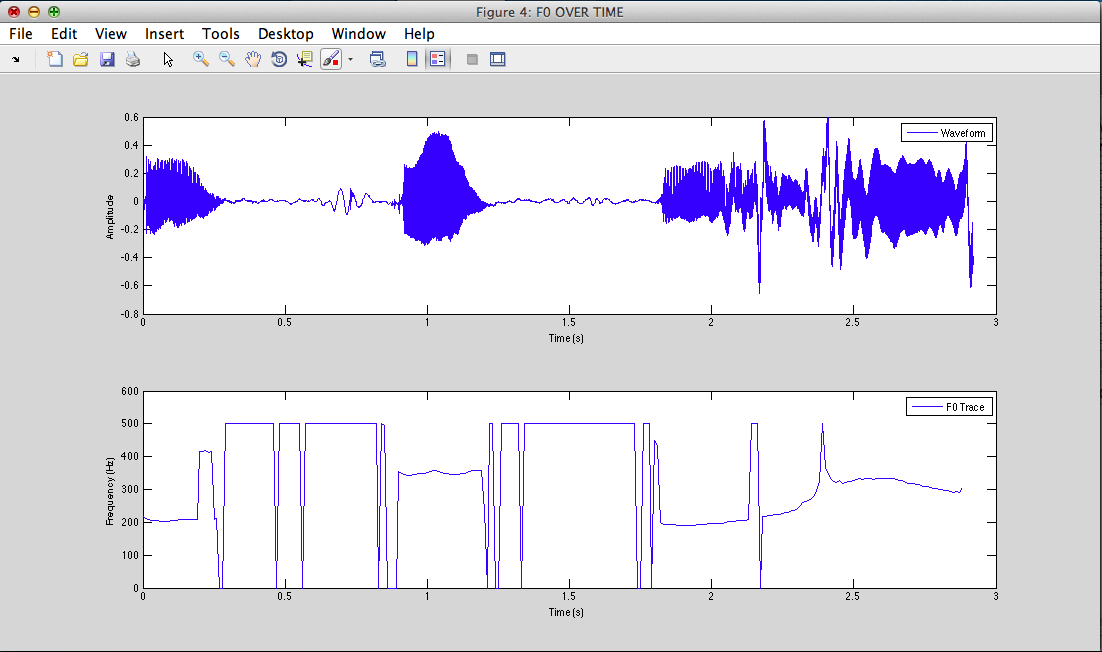
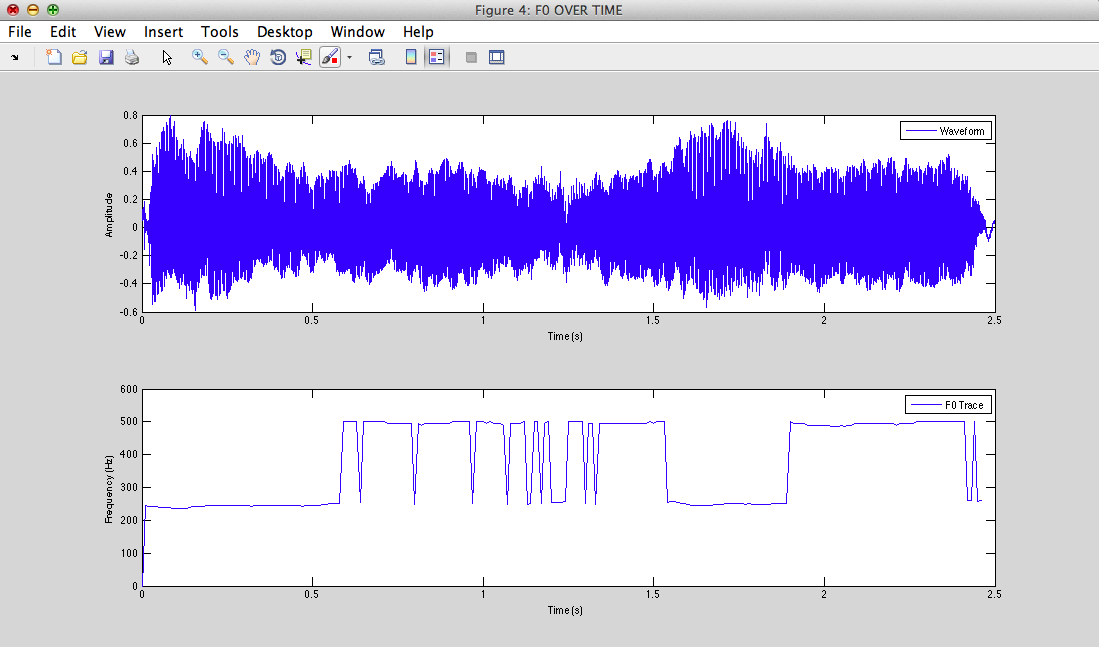
II - 2) Glottal signal : estimation of F0
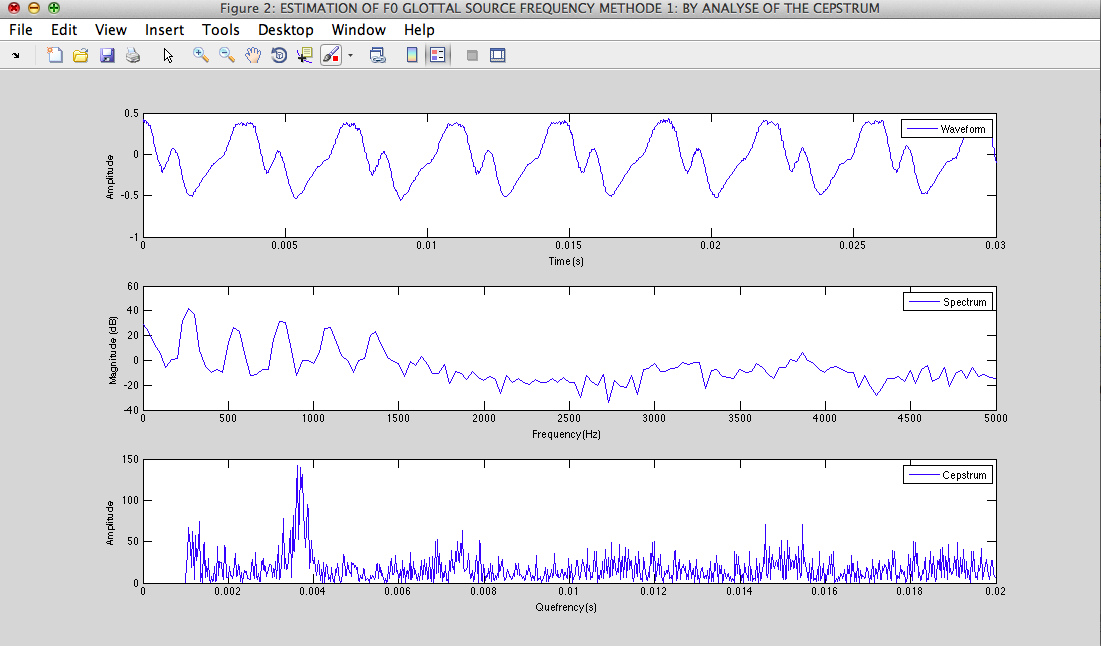
F0=275.453Hz
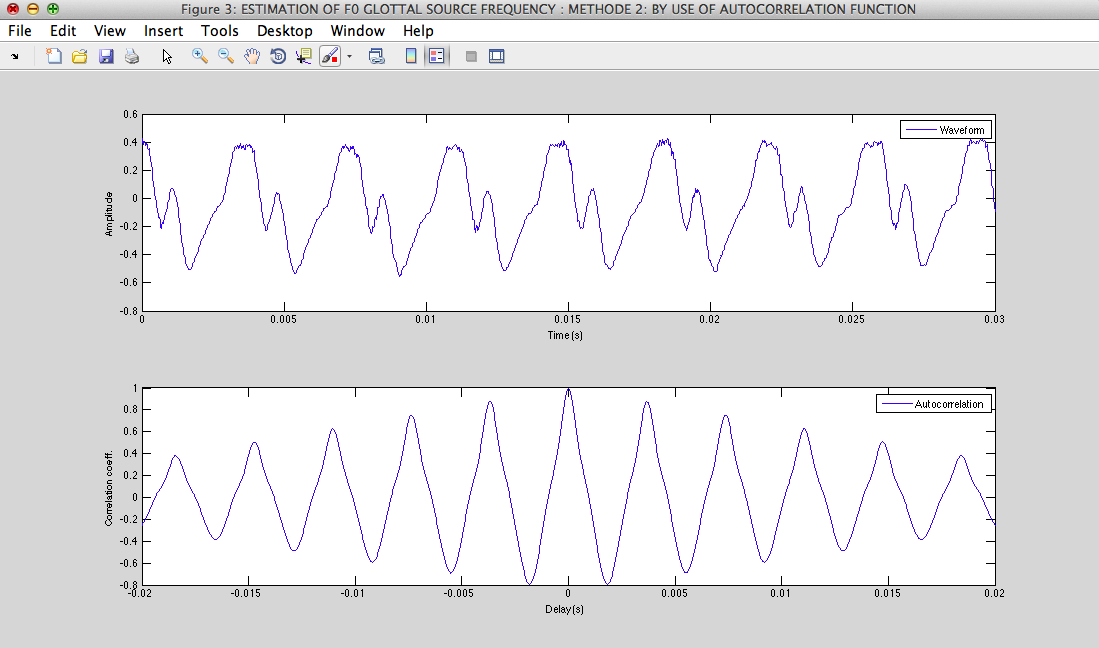
rmax=0.87549 Fx=270.221Hz
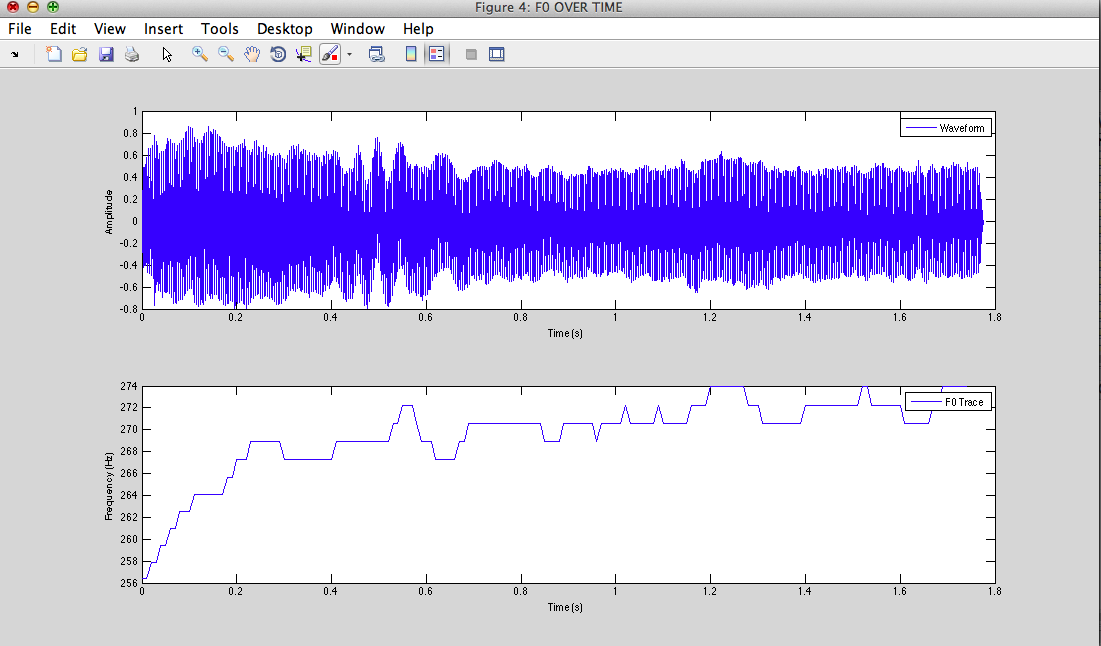
II - 3) Filtration by the cavities
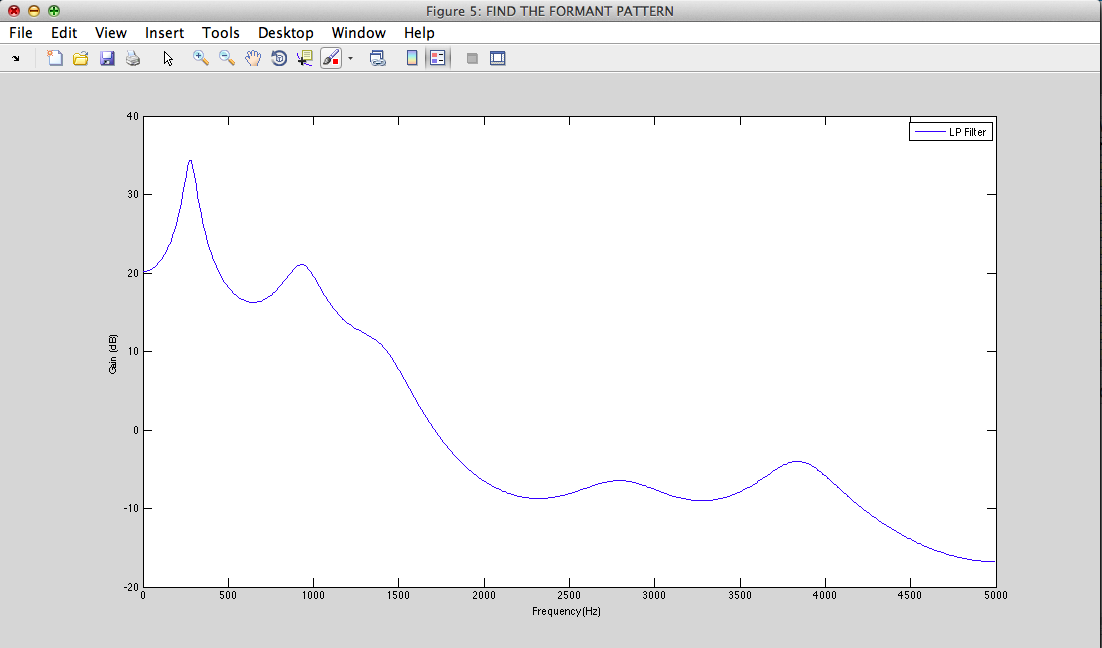
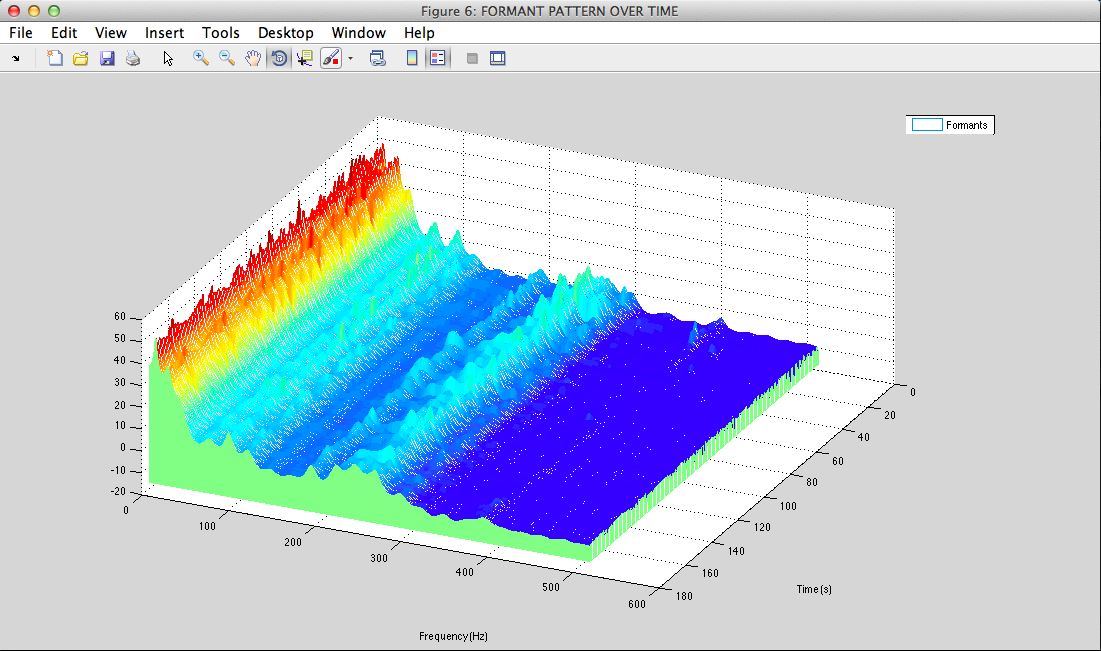
II - 4) Exemples
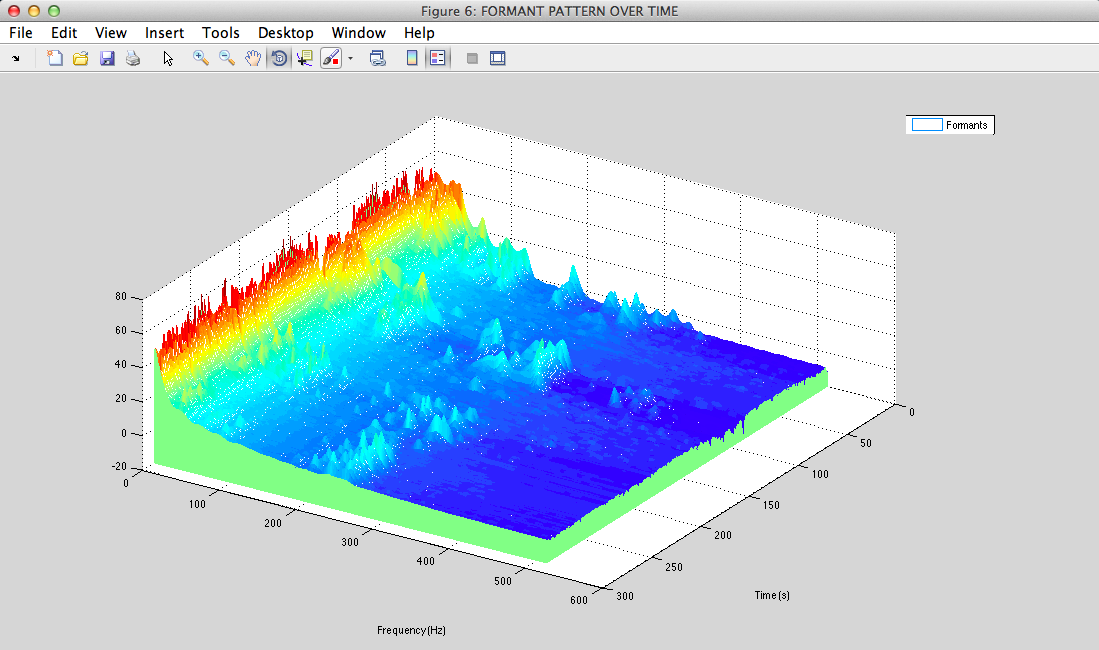
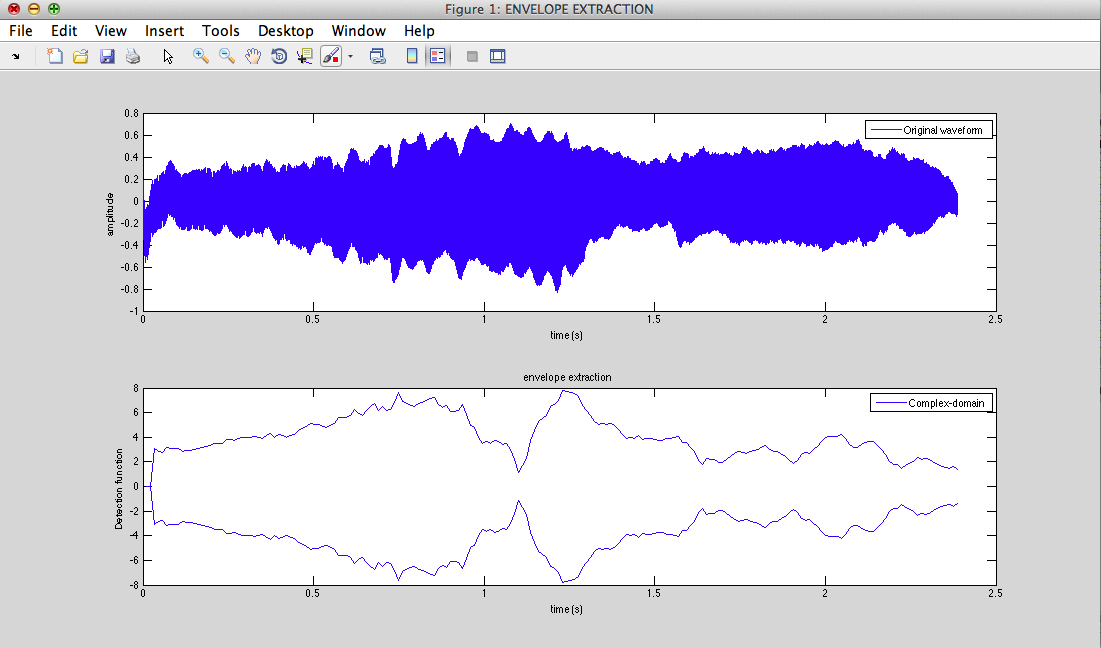
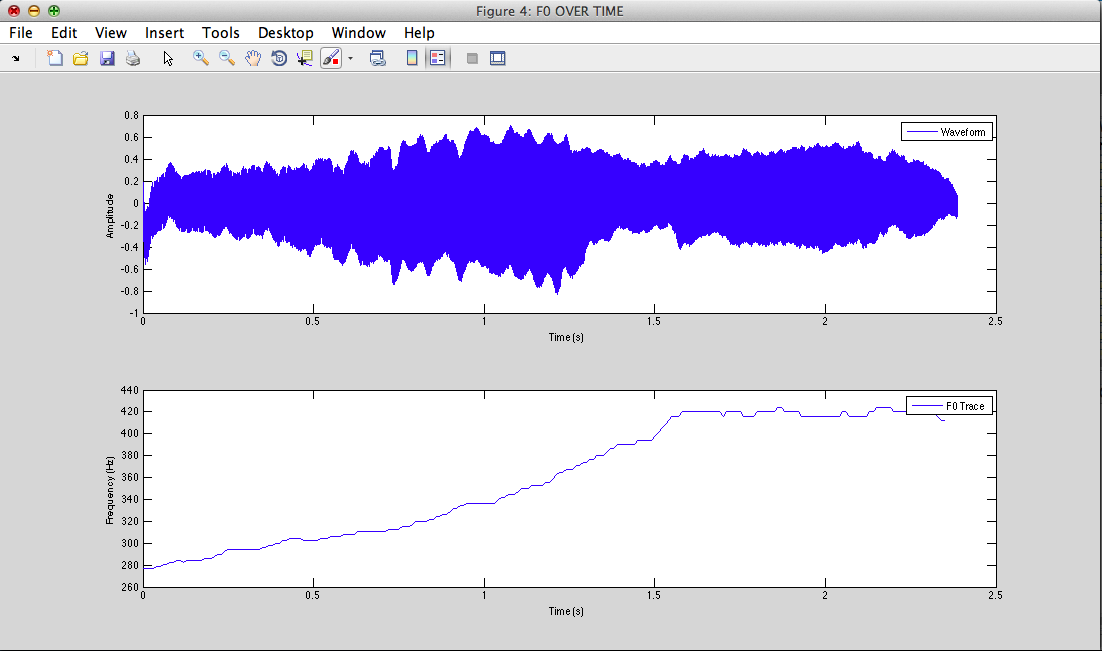
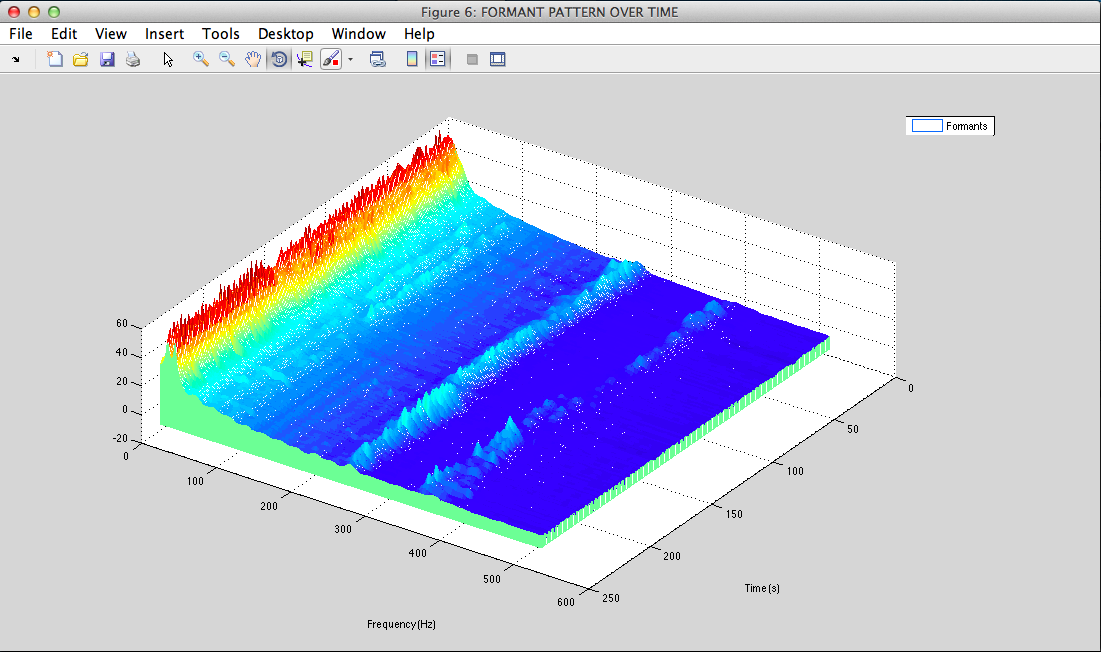
III - From physics to signal
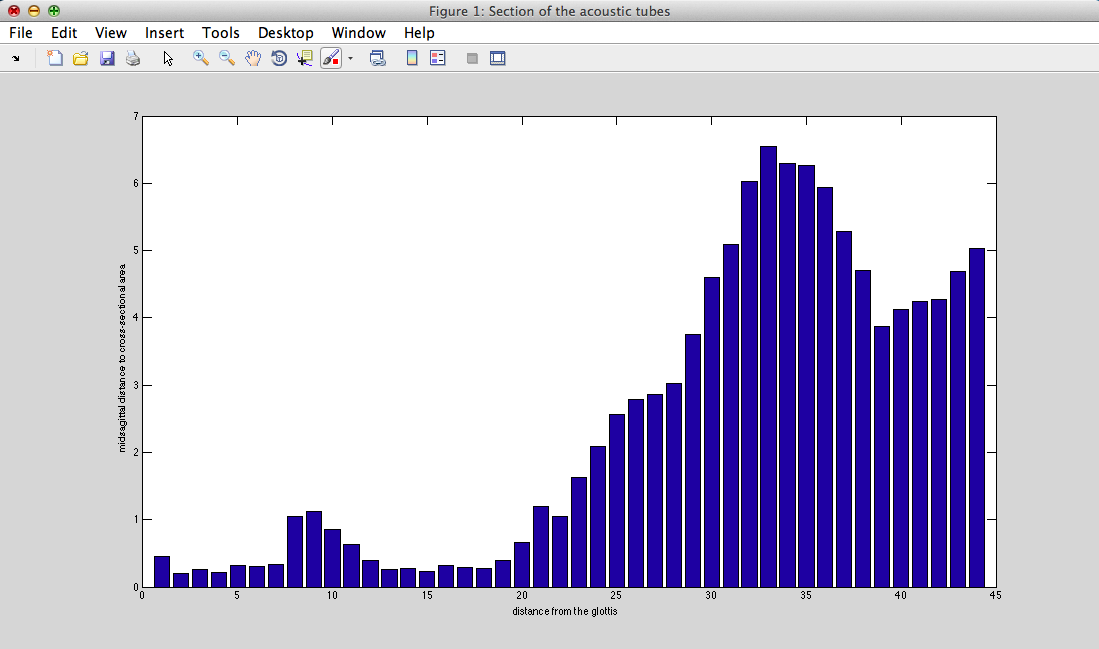
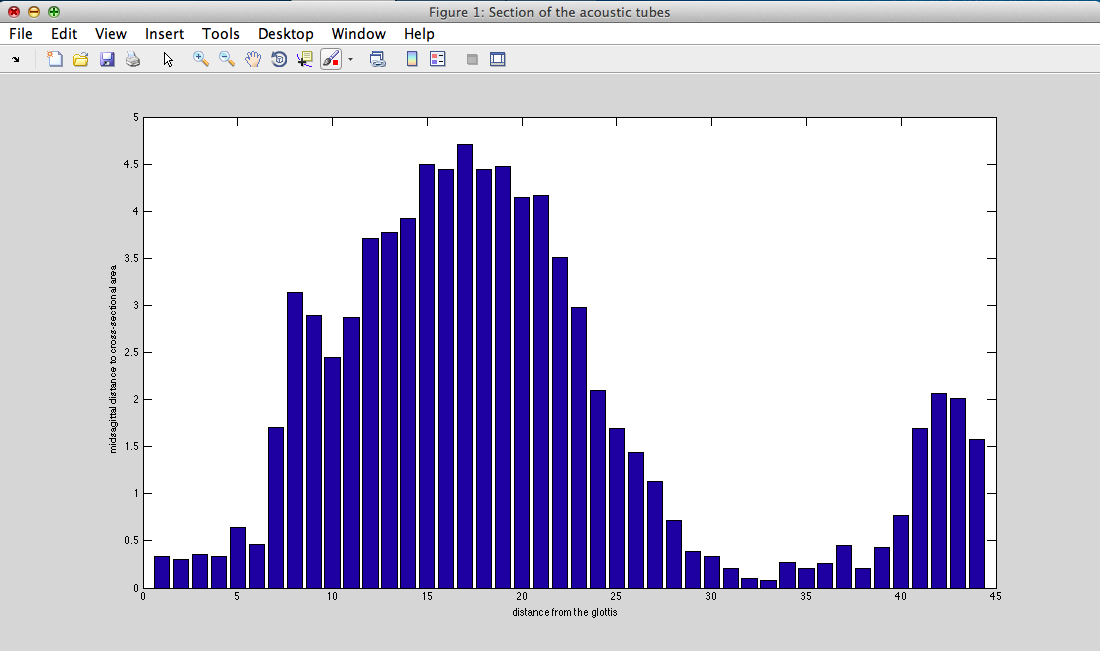
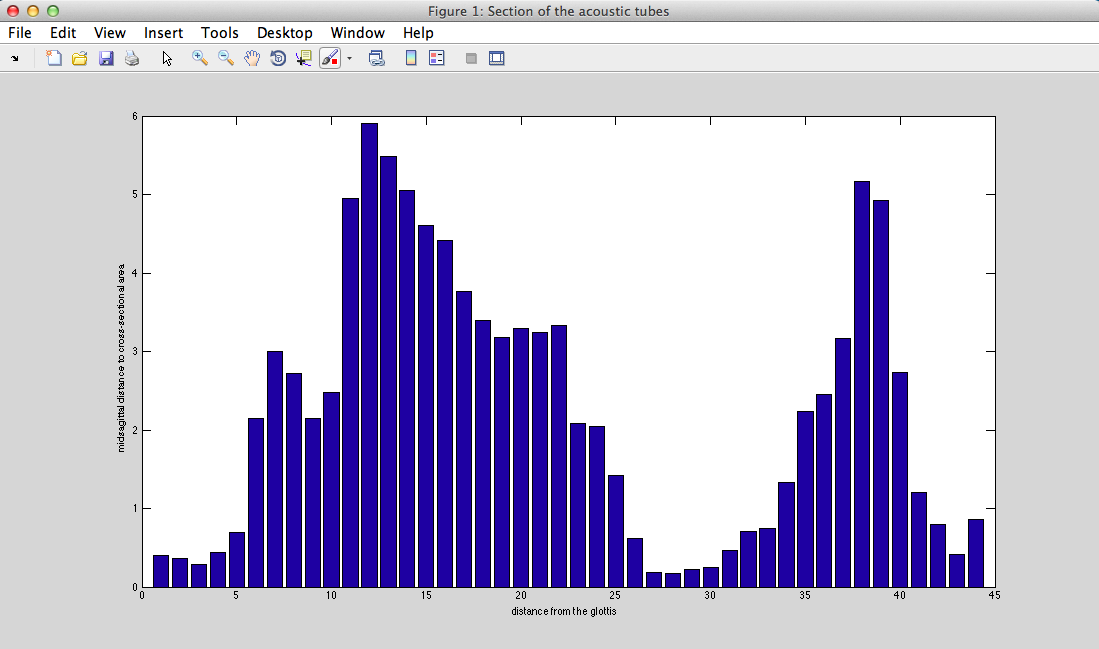
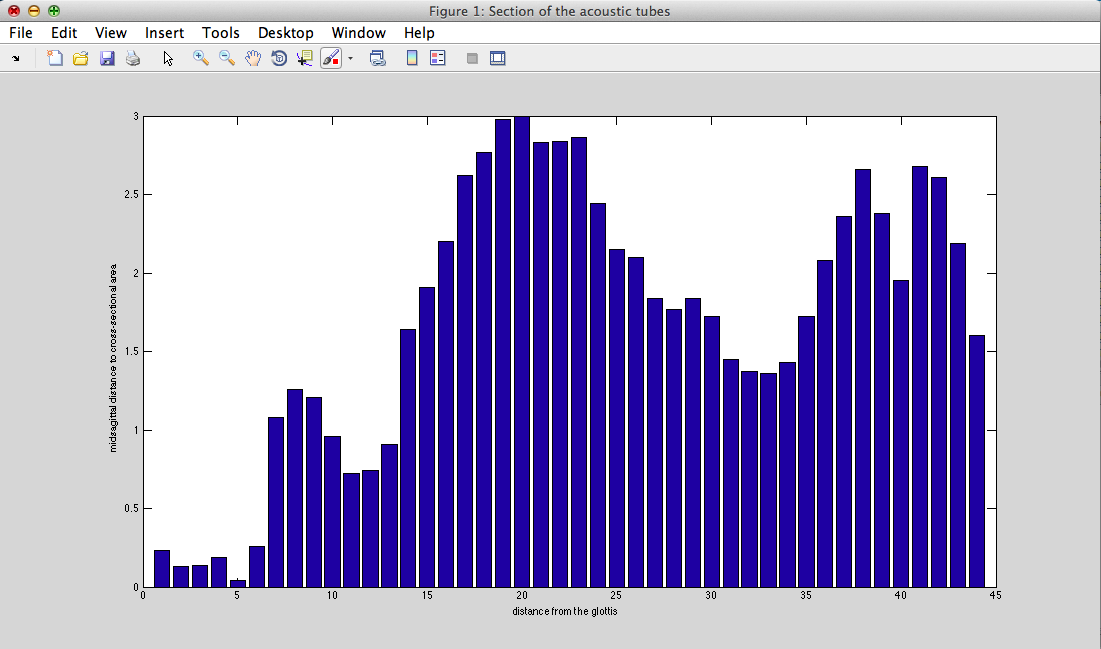
III - 1) Vocal tract shape
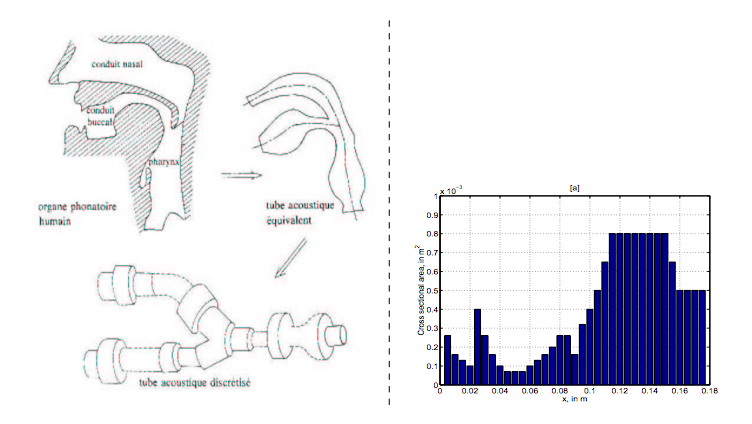
from (8)
III - 2) Scattering equation
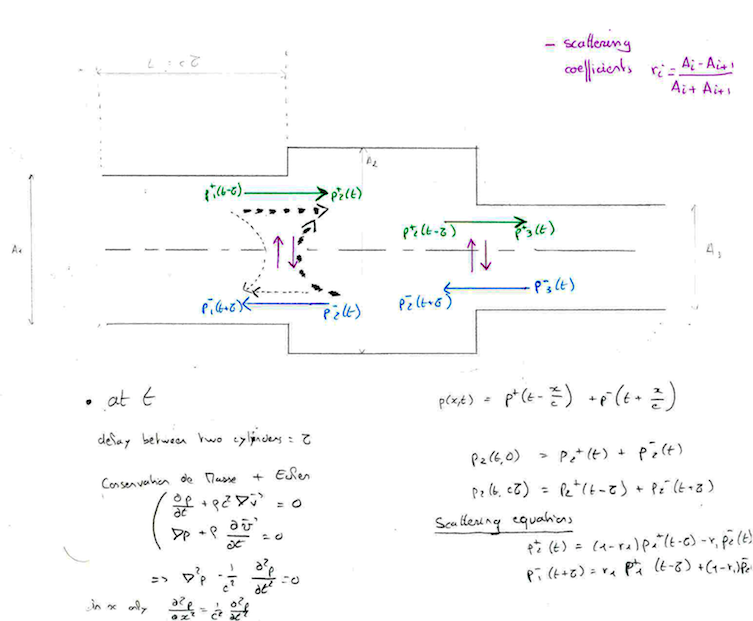
III - 3) Glottal signal model
- The Rosenberg trigonometric source model
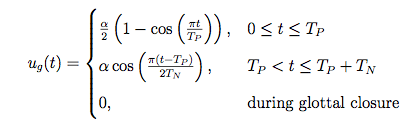
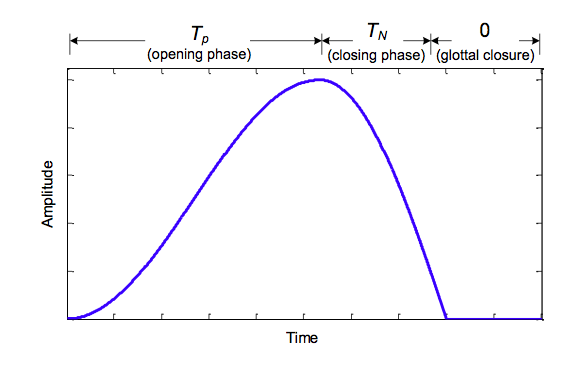
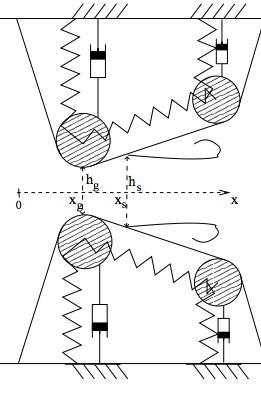
- The LF model with 5 parameters
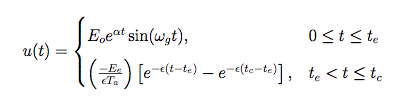
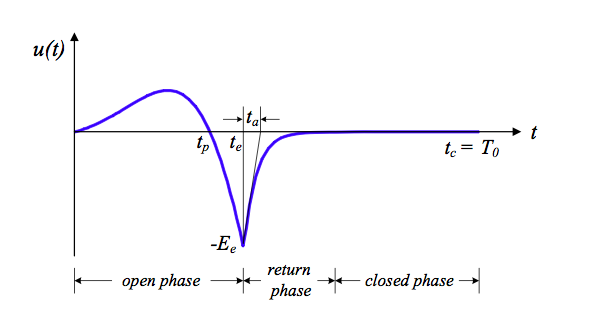
- Model based on High-speed imaging of the vocal folds with synchronous audio recordings (Yen-Liang Shue)
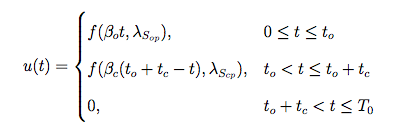
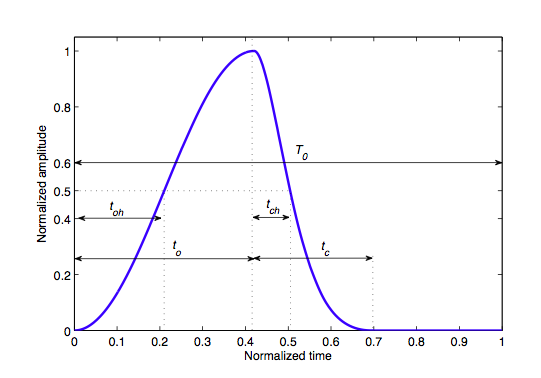
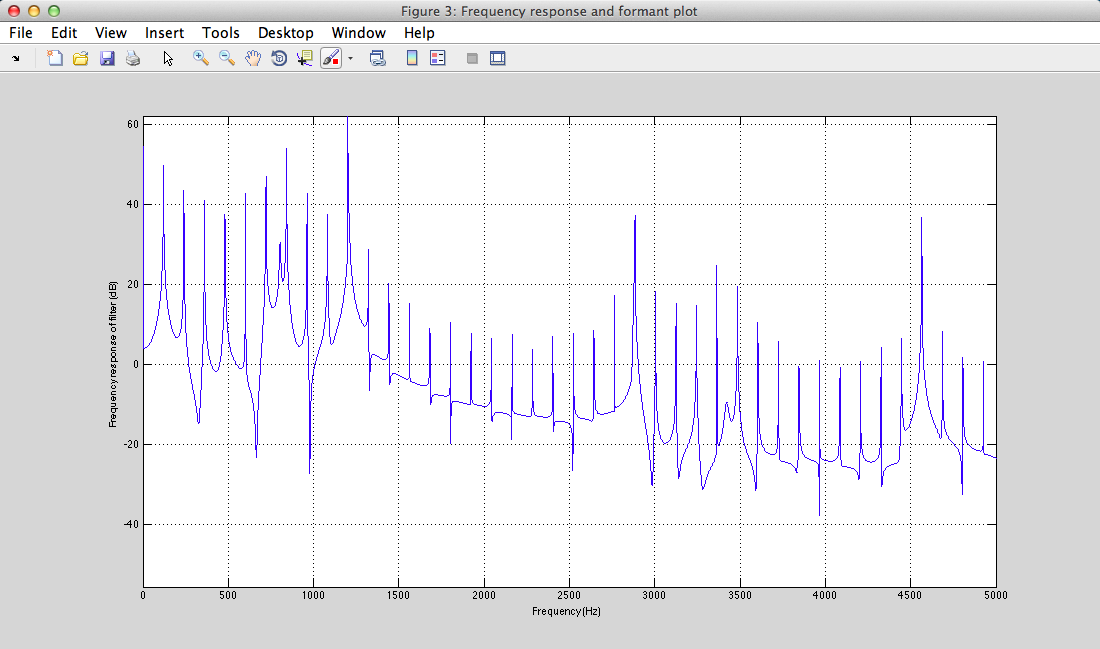
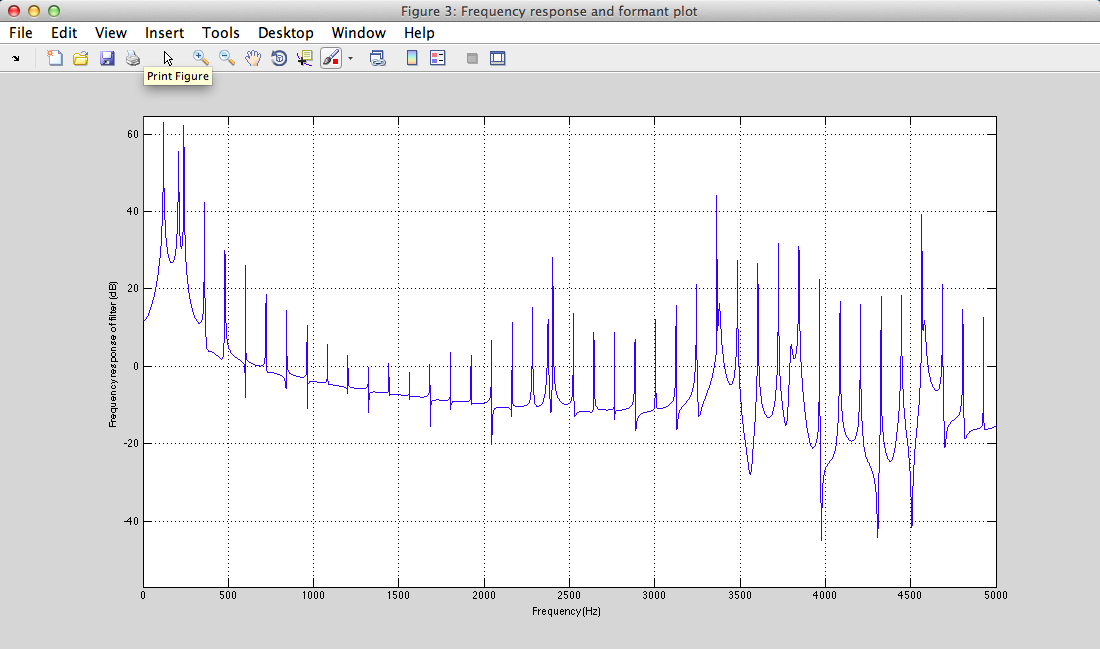
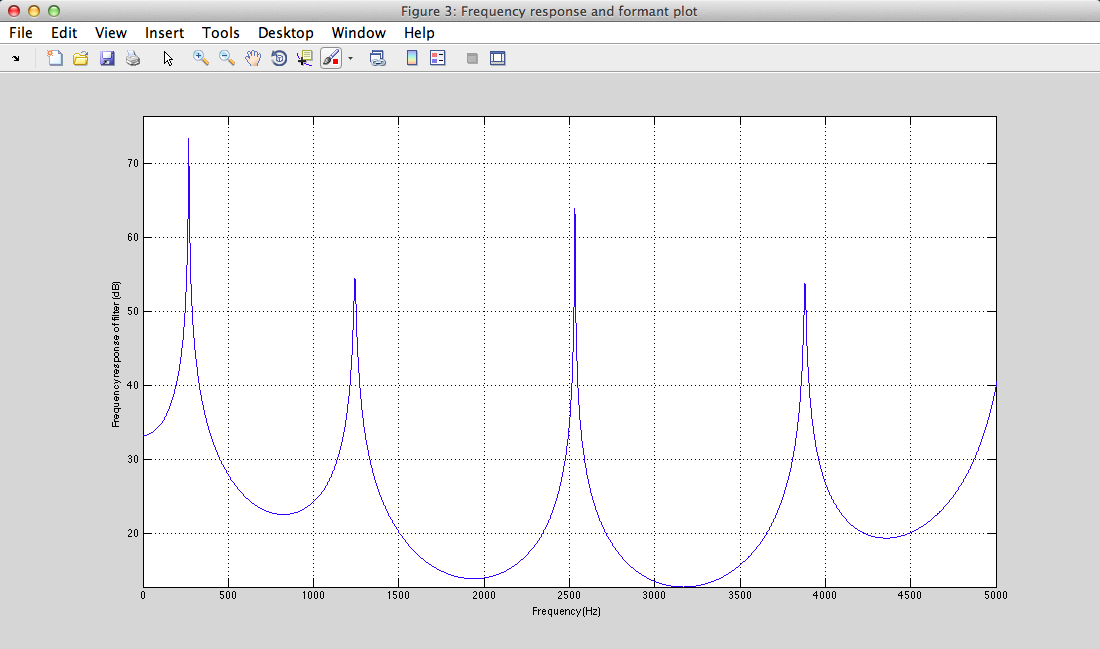
III - 4) Results
Play Result
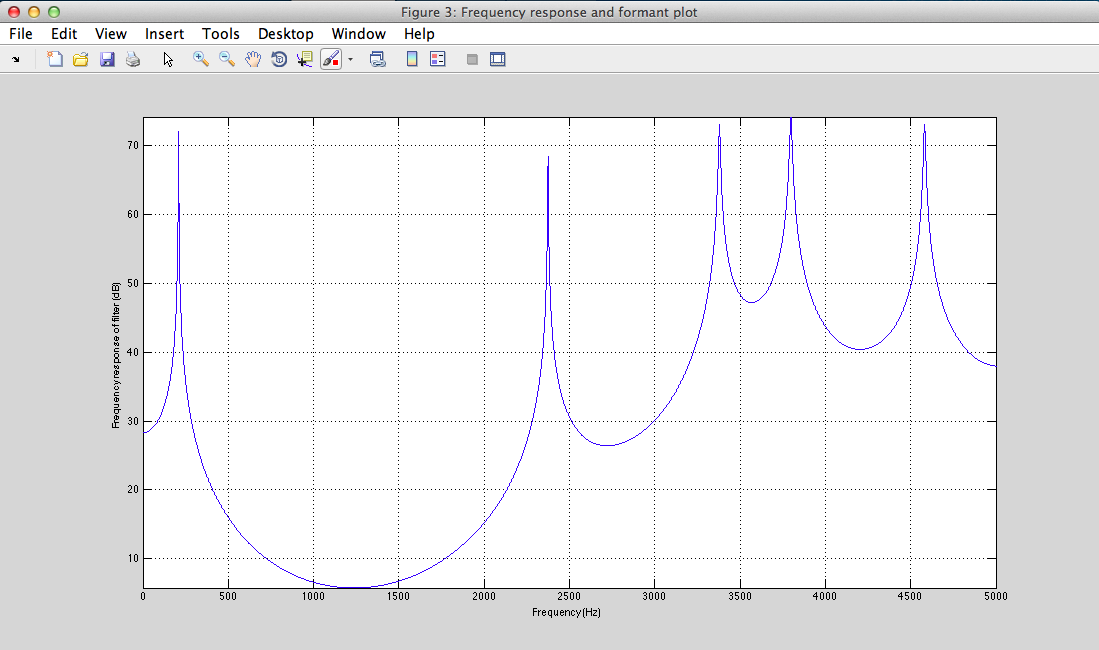
Play Result
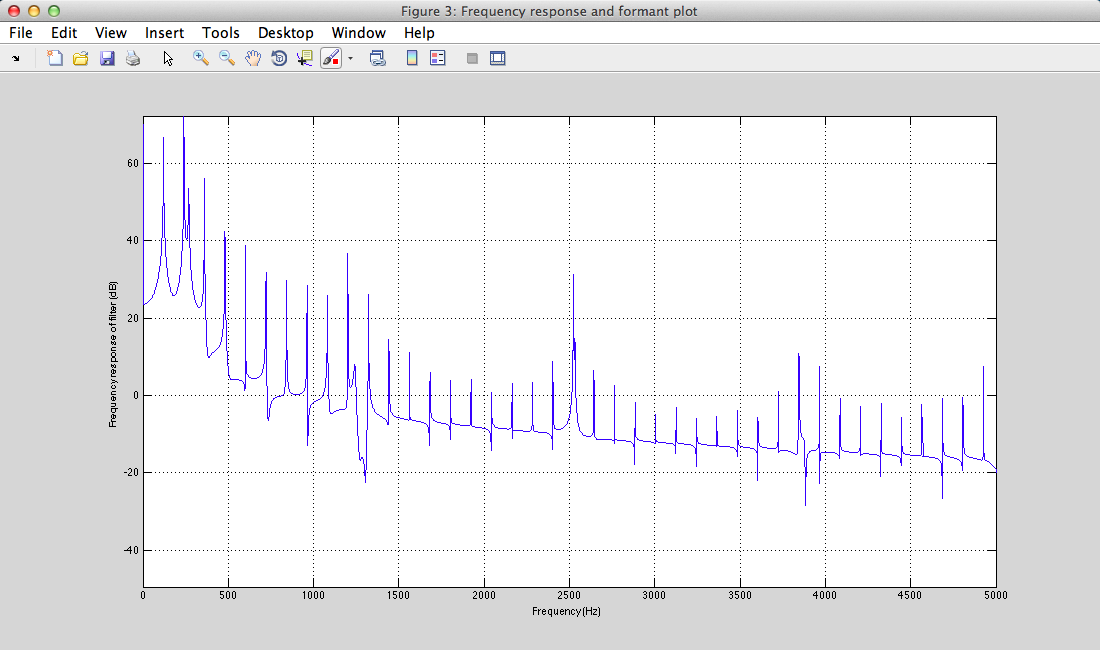
Play Result
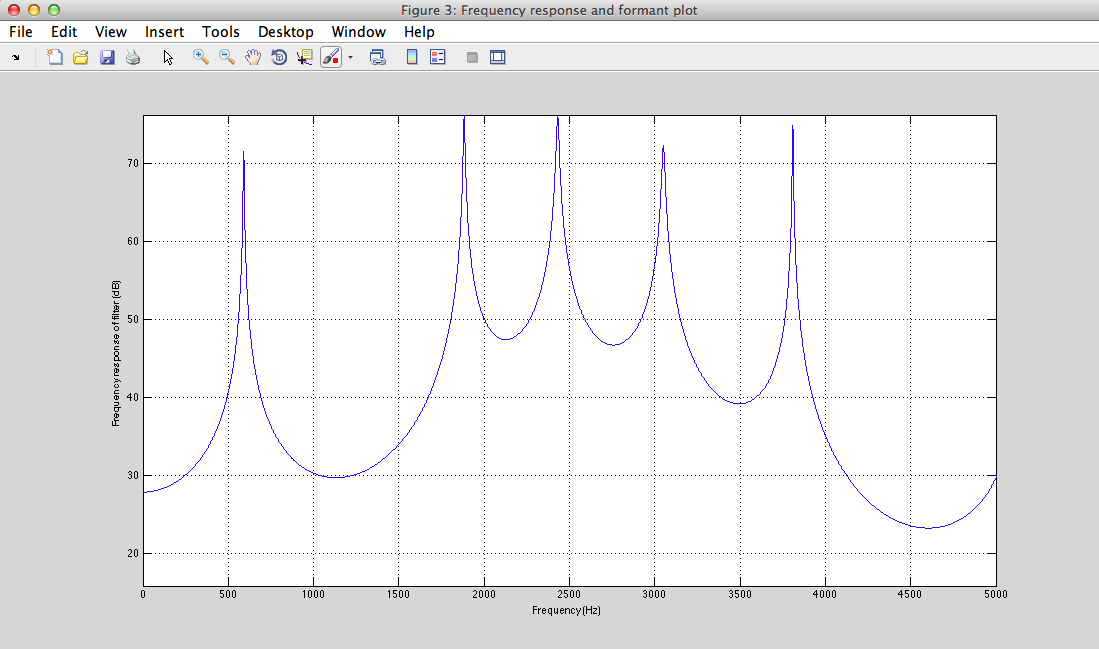
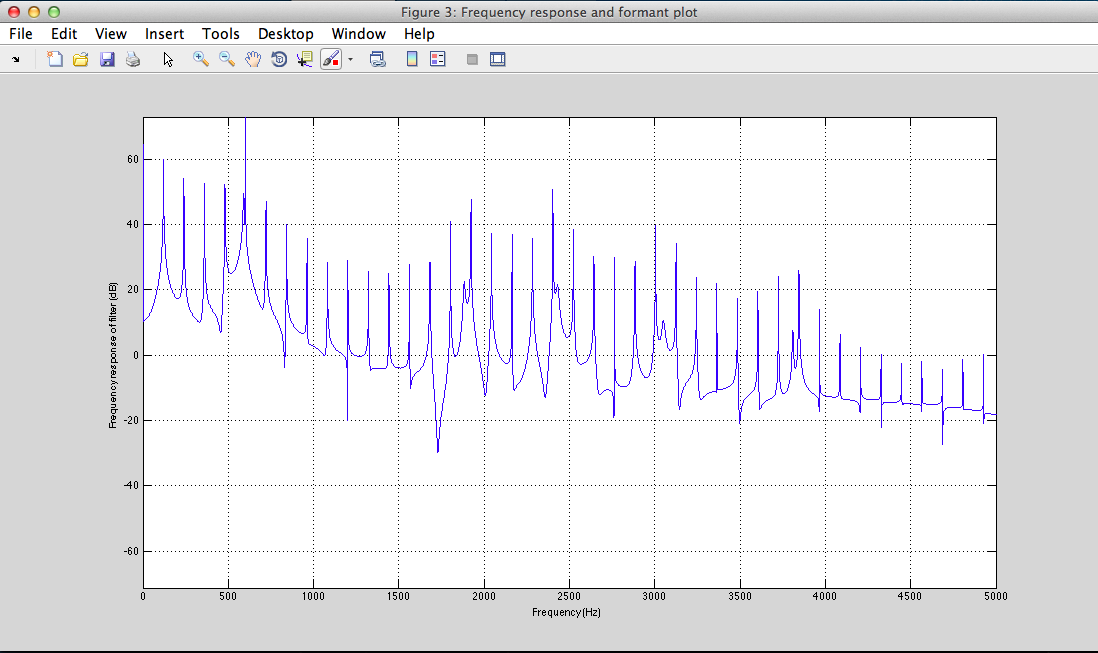
Play Result
IV - Information theory point of view
IV - 1) Entropy in speech in the audio signal paradygm
- Continuous signal fidelity criterium -> 128 values (hyperquantization)
- Efficiency is not everything, vocodeur can transmit only one voice -> waveform decoding requieres 15,000 bit/s
- Pulse Code Modulation 30,000 to 60,000 bit/s
- Vocodeur 2,400 bit/s
- Linear predictive Machines gives very good speech at 9,600 bit/s, intelligible speech at 2,400 bit/s, barely intelligible speech at 600 bit/s.
- french literature raw file (Proust) : entropy=7.40137 bit/sample
- english talk : entropy=8.43616 bit/sample
IV - 2) State of the art of low bit rate coding
- Raw audio = 705,600 bit/s
- mp3 = 128,000 bit/s
- very low bot rate coding (11) go down to 64,000 bit/s
- CTaac-Plus = 48,000 bit/s (12)
IV - 3) Bits/seconds in physical modeling
- 44 for vocal tract
- Tension of glottis = F0
- Breathiness
- Lips motion, area 2 param