
This week, I wanted to build off last week's work and continue iterating on the speech-to-text function. I used the same connection from last week (XIAO-ESP32S3 and Adafruit I2S Mems mic breakout board) and started from where I left off last week, which was being able to run the speech-to-text from WiFi connection, but only seeing the results printed in console. You can see my progress from networking here.
First, I had to get the transcribed text to a webpage. I had to adapt my recognizer stream from the Google Speech API so that it would keep track of the connected clients and send the transcript to them whenever I wrote to the STT stream. Here is the new recognizerStream function I (with the help of GPT) wrote.
// Array of connected WebSocket clients
let connectedClients = [];
// Function to create a new recognize stream
const createRecognizeStream = () =>
speechClient
.streamingRecognize(request)
.on("error", (err) => console.error("Speech API Error:", err))
.on("data", (data) => {
if (data.results[0] && data.results[0].alternatives[0]) {
const transcript = data.results[0].alternatives[0].transcript;
console.log(`Transcription: ${transcript}`);
// Broadcast transcription to all connected clients
connectedClients.forEach((client, i) => {
if (client.readyState === WebSocket.OPEN) {
client.send(transcript);
} else {
connectedClients.splice(i, 1); // Remove disconnected clients
}
});
}
});
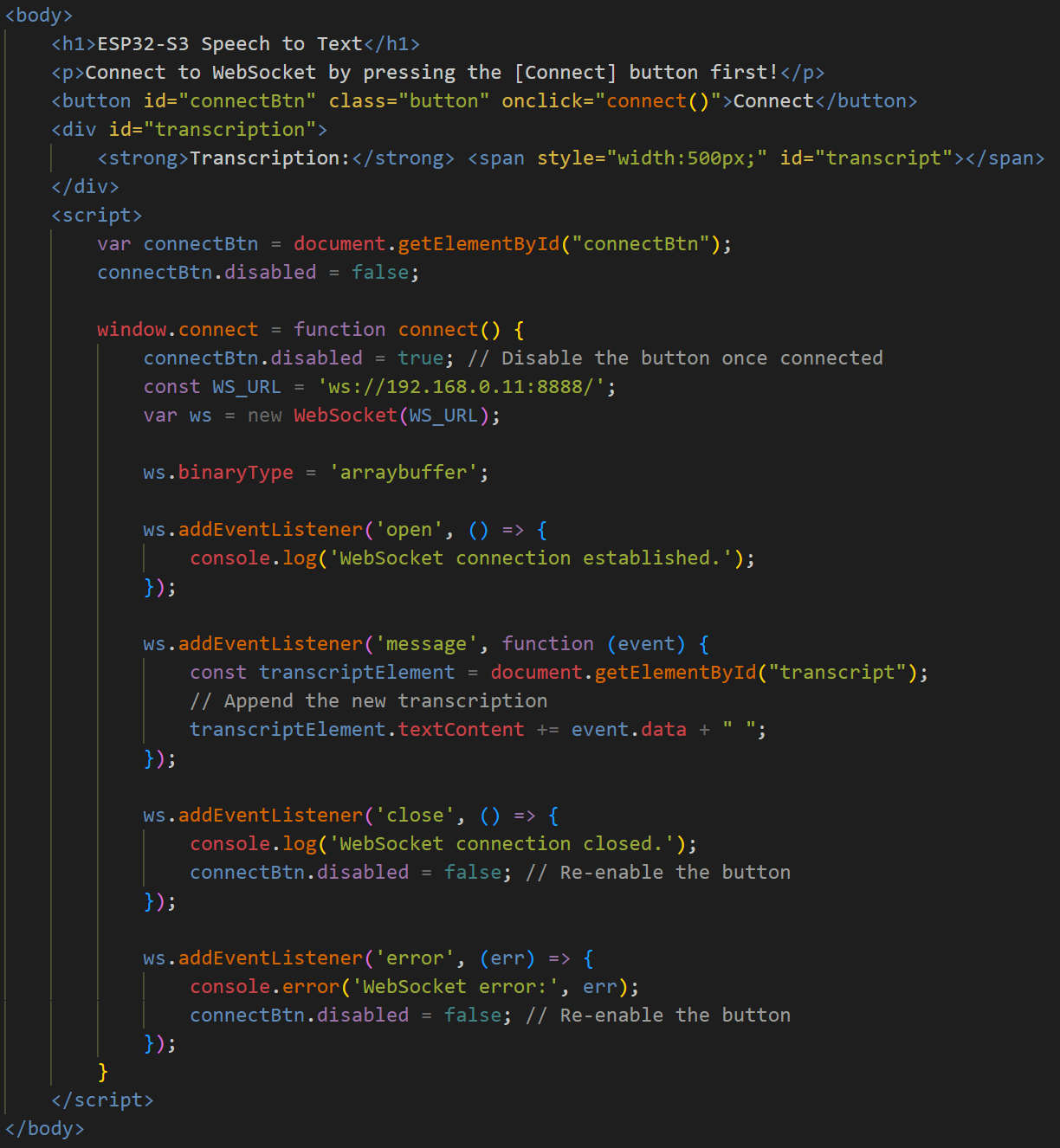
This is what the adapted html page looked like so that it would just display the transcription. I adapted it from the youtube tutorial found in week 11.
I realized that the mic performance was variable and sometimes if the bottom port was blocked, would have very poor sound quality. Once I got it working, I was able to see relatively accurate transcription at reasonably high latency as well. Here is an example of me speaking into the mic.
This is the full code block for the websocket server using the express framework to connect to the audio_client.html page.
const path = require("path");
const WebSocket = require("ws");
const express = require("express");
const speech = require("@google-cloud/speech");
const app = express();
const speechClient = new speech.SpeechClient(); // Google Cloud Speech client
// Ports
const WS_PORT = process.env.WS_PORT || 8888;
const HTTP_PORT = process.env.HTTP_PORT || 8000;
// WebSocket server
const wsServer = new WebSocket.Server({ port: WS_PORT }, () =>
console.log(`WS server is listening at ws://localhost:${WS_PORT}`)
);
// Speech-to-Text configuration
const request = {
config: {
encoding: "LINEAR16",
sampleRateHertz: 16000,
languageCode: "en-US",
},
interimResults: false, // Set to true if you want interim results
};
// Array of connected WebSocket clients
let connectedClients = [];
// Function to create a new recognize stream
const createRecognizeStream = () =>
speechClient
.streamingRecognize(request)
.on("error", (err) => console.error("Speech API Error:", err))
.on("data", (data) => {
if (data.results[0] && data.results[0].alternatives[0]) {
const transcript = data.results[0].alternatives[0].transcript;
console.log(`Transcription: ${transcript}`);
// Broadcast transcription to all connected clients
connectedClients.forEach((client, i) => {
if (client.readyState === WebSocket.OPEN) {
client.send(transcript);
} else {
connectedClients.splice(i, 1); // Remove disconnected clients
}
});
}
});
// Handle WebSocket connections
wsServer.on("connection", (ws) => {
console.log("New WebSocket connection");
connectedClients.push(ws);
// Create a new recognize stream for each client
const recognizeStream = createRecognizeStream();
// Handle incoming audio data
ws.on("message", (data) => {
if (Buffer.isBuffer(data)) {
recognizeStream.write(data); // Send audio data to the Speech-to-Text API
}
});
// Cleanup on client disconnect
ws.on("close", () => {
console.log("WebSocket connection closed");
recognizeStream.end(); // Close the recognize stream
connectedClients = connectedClients.filter((client) => client !== ws);
});
ws.on("error", (err) => {
console.error("WebSocket error:", err);
});
});
// HTTP server
app.use("/image", express.static("image"));
app.use("/js", express.static("js"));
app.get("/audio", (req, res) =>
res.sendFile(path.resolve(__dirname, "./speech_client.html"))
);
app.listen(HTTP_PORT, () =>
console.log(`HTTP server listening at http://localhost:${HTTP_PORT}`)
);
Technically, this would have satisfied this week's assignment, but in the spirit of spiral development, I wanted to see if I could query GPT with the transcription for progress on my magic mirror. To do so, I would have to use the openai package and call the GPT API. Conveniently enough, I could just ask GPT to help me out with this!
Here is my code in the Node server
// Endpoint to interact with GPT using transcription
app.use(express.json()); // To parse JSON body
app.post('/ask-gpt', async (req, res) => {
try {
const { transcription, prompt } = req.body; // Get transcription and custom prompt from client
// Prepare the message for GPT, combining the transcription with the custom prompt
const message = prompt ? `${prompt}\nTranscription: ${transcription}` : transcription;
// Send the transcription to GPT with the custom prompt
const response = await openai.chat.completions.create({
model: 'gpt-3.5-turbo', // or another model like gpt-4
messages: [{ role: 'user', content: message }],
});
res.json({ reply: response.choices[0].message.content }); // Return GPT's response
} catch (err) {
console.error('Error interacting with GPT:', err);
res.status(500).json({ error: 'Something went wrong with GPT' });
}
});
function askGPT() {
const customPrompt = "You are the Magic Mirror from Snow White. Only respond in rhyme and up to 4 lines of poetry.";
// Send transcription and optional custom prompt to the server for GPT processing
fetch('/ask-gpt', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ transcription: transcriptionText, prompt: customPrompt }),
})
.then(response => response.json())
.then(data => {
const responseTextElement = document.getElementById("responseText");
responseTextElement.textContent = data.reply; // Display GPT's reply
})
.catch(error => {
console.error('Error:', error);
alert('Failed to get GPT response');
});
}
And here is the code in the html page.
As you can see, I included the custom prompt of "You are the Magic Mirror from Snow White. Only respond in rhyme and up to 4 lines of poetry." This led to some fun testing, once I got everything working! I also added a button to clear the transcript for when I wanted to renew what I was sending to GPT.


You can see the latency in this video here, both for the speech-to-text via WiFi and the GPT response. I didn't remember to rhyme, but still got a good response out of my prompted GPT. Next steps will include text-to-speech, as well as thinking about the user experience -- ideally, I would implement detection of speech start and stop, and users would be prompted to speak in continuous phrases, so that the server will automatically query GPT once it hears a complete utterance. Overall, very excited to see it starting to come together!