-

- Computer-Aided Design 01
- Parametric Construction 02
- Electronics Production 03
- 3D Printing 04
- Electronics Design 05
- Computer-Controlled Machining 06
- Embedding Programming 07
- Molding + Casting 08
- Output Devices 09
- Machine Design 10
- Input Devices 11
- Interface + App Programming 12
- Networking + Communications 13
- Composites 14
- Final Project 15
HOW TO MAKE (ALMOST) ANYTHING
Lily Gabaree
Computer-Aided Design + Final Project Planning
To start out, I’m thinking about expanding on an idea I started prototyping in the spring: representing conversations in other forms, such as in liquid mixtures (consumable or otherwise). A good conversation is presumed to have a relative balance of speakers. What if our own contributions to a conversation were realized in real chemistry?
VOICE is a proposed system of devices to capture conversations in another state. Among two speakers, VOICE would use two proximate microphones to detect who is speaking at a given time. In its simplest form, VOICE would then squirt out one of two liquids, depending on who was speaking at a given time - such as an acid or base, or a red or blue color.
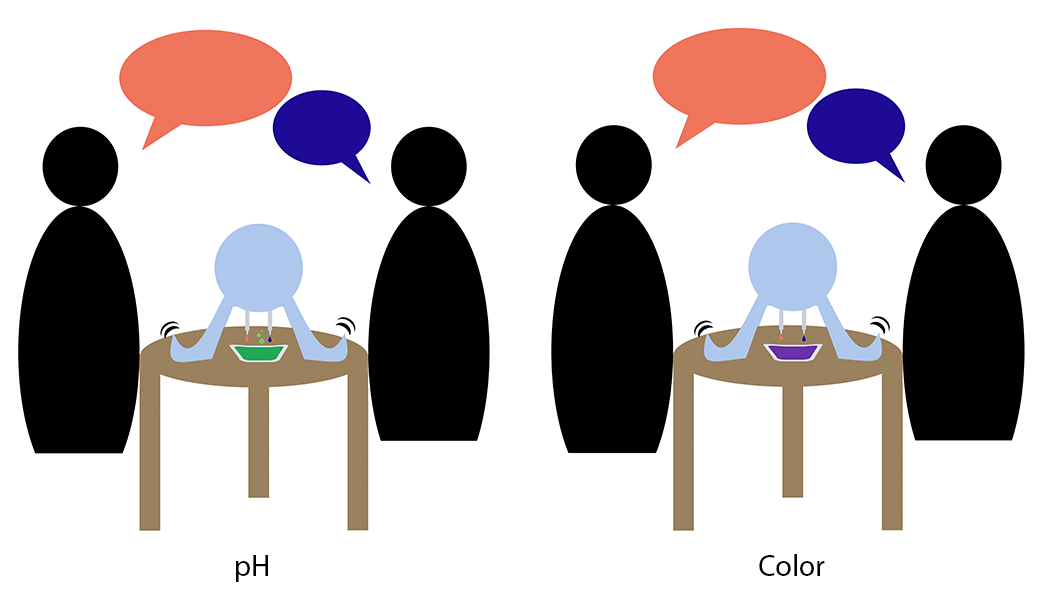
Alternatively, the two speakers’ dynamic could be rendered a little less directly by mapping its qualities to one of a variety of presets (e.g., cocktail mixes), to be consumed by the two speakers.

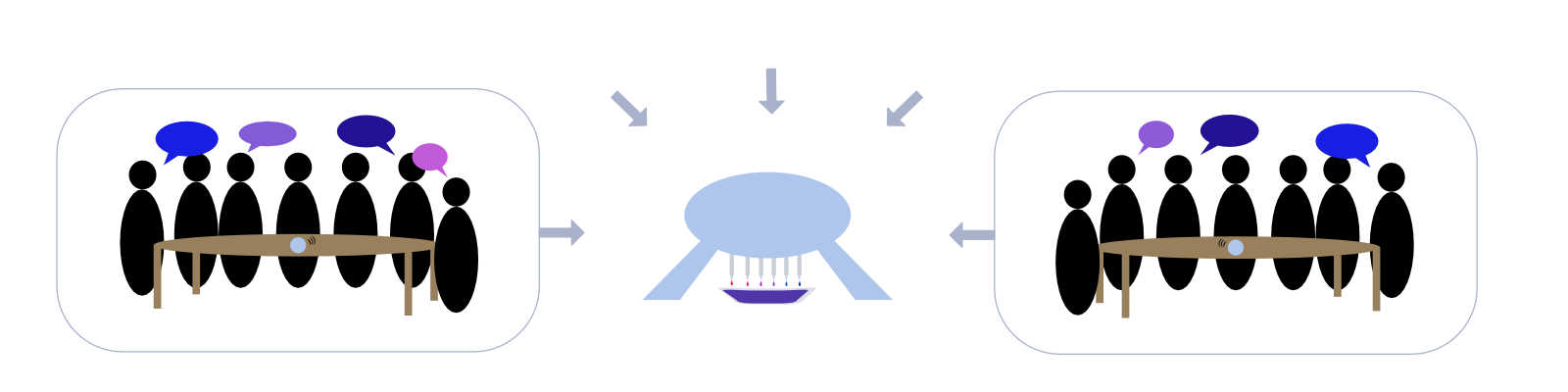
I am also interested in depicting conversations by vocal range - which can be loosely mapped to biological sex in adults. A male/female range dichotomy would be inaccurate and reductive, but I am curious about translating a range of voices into a range of outputs, and possibly having those outputs along a gradient (e.g. color) that can be easily interpreted as a summation of all inputs. It might be interesting to see the resulting mixtures in different environments (e.g., a large technical institution). This could involve IoT devices detecting vocal ranges in different spaces around a campus, and then having that data depicted in a central vessel.

Product Rendering
This week, I'm trying out Fusion 360 for modeling and rendering. Here's a possible model, along with a very rough initial prototype of the feel of the experience.

But I'm still brainstorming...not sure yet if this will be my final project. I'm also thinking about: interactive fountains (driven by gesture, conversation, or maybe drumming); theremins; and devices that play drums along with any rhythms detected in the surrounding environment.